信頼性の高い、本番環境対応システムのために、エージェントで構造化された入力と出力を使用する方法を学習します。
Agno エージェントは、単純な文字列ベースのインタラクションから Pydantic モデルを使用した構造化されたデータ検証まで、様々な形式の入出力をサポートしています。
Agno 2.x : Learn : エージェント – 入出力
作成 : クラスキャット・セールスインフォメーション
作成日時 : 10/24/2025
バージョン : Agno 2.2.1
* 本記事は docs.agno.com の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています。スニペットはできる限り日本語を使用しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
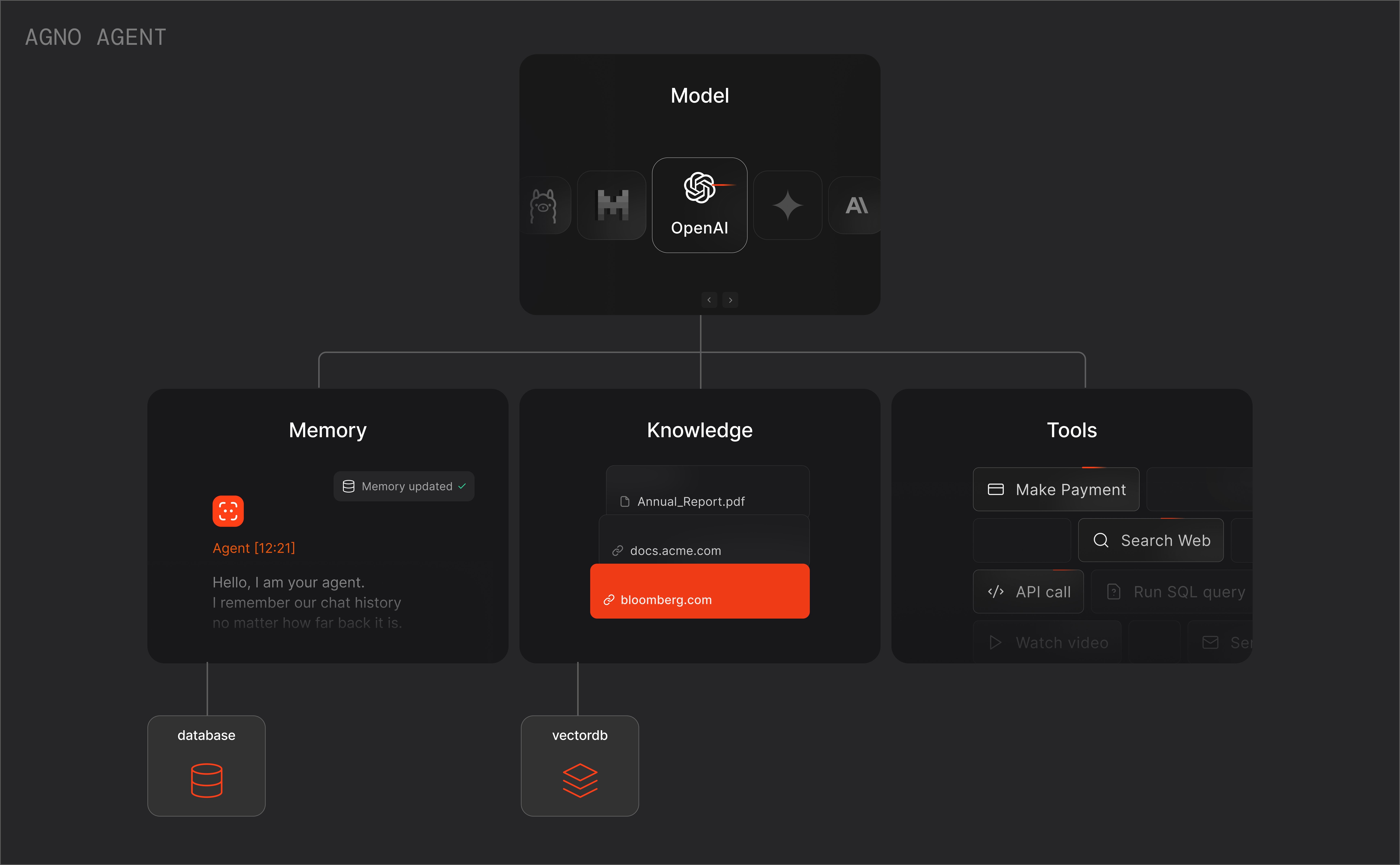
Agno 2.x : Learn : エージェント – 入出力
信頼性の高い、本番環境対応システムのために、エージェントで構造化された入力と出力を使用する方法を学習します。
Agno エージェントは、単純な文字列ベースのインタラクションから Pydantic モデルを使用した構造化されたデータ検証まで、様々な形式の入出力をサポートしています。
最も標準的なパターンは、str 入力と str 出力を使用することです :
from agno.agent import Agent
from agno.models.openai import OpenAIChat
agent = Agent(
model=OpenAIChat(id="gpt-5-mini"),
description="あなたは映画の脚本を書きます。",
)
response = agent.run("東京に住む少女についての映画の脚本を書きます")
print(response.content)
出力例
いいですね。まず確認させてください — どんな脚本にしますか?長さやジャンルの好みを教えてください。いくつか例を用意しました。希望の番号を教えていただければ、その方向で脚本(短編:約10〜20分、もしくは長編の冒頭/構成案)を書きます。 選択肢(例) 1) 「現実派・青春ドラマ」 — 東京で悩みながら成長する少女の物語。家族問題・友情・進路の葛藤を繊細に描く。 2) 「魔法的リアリズム(東京×ちょっと不思議)」 — 日常に小さな奇跡が混じるタイプ。街の片隅で出会った不思議な出来事が少女の視点を変える。 3) 「ミステリー/サスペンス」 — 東京を舞台にした軽い謎解き。失われたもの、過去の痕跡を追う少女の捜索劇。 決めかねる場合は「おまかせ」でも構いません。ジャンルのほか、主人公の年齢(小学生/中学生/高校生/20代)、トーン(シリアス/軽快/ほろ苦い)、映像尺(短編/長編)など指定があれば反映します。どれにしますか?また、先に冒頭シーン(数ページ)だけ見てみたい場合も対応します。
構造化出力
私たちのお気に入りの機能の一つは、エージェントを使用して構造化されたデータ (i.e. pydantic モデル) を生成することです。これは一般には「構造化出力」と呼ばれます。この機能を使用して、特徴抽出、データ分類、フェイクデータの生成 等を行うことができます。ベストな点は、関数呼び出し、知識ベースやその他あらゆる機能と連携できることです。
構造化出力は、非構造化テキストでなく、一貫性と予測可能なレスポンス形式を必要とする、プロダクション・システムにおいてエージェントの信頼性を向上させます。
MovieScript を記述する Movie エージェントを作成しましょう。
- 構造化出力の例
movie_agent.py
from typing import List from rich.pretty import pprint from pydantic import BaseModel, Field from agno.agent import Agent from agno.models.openai import OpenAIChat from dotenv import load_dotenv load_dotenv() class MovieScript(BaseModel): setting: str = Field(..., description="大ヒット映画にふさわしい素敵な舞台を提供してください。") ending: str = Field(..., description="映画のエンディング (結末)。それがない場合は、ハッピーエンドでお願いします。") genre: str = Field( ..., description="映画のジャンル。それがない場合は、アクション、スリラー、またはロマンティックコメディを選択してください。") name: str = Field(..., description="この映画に名前を付けてください") characters: List[str] = Field(..., description="この映画の登場人物たちの名前。") storyline: str = Field(..., description="映画のストーリーの3センテンス(文)。エキサイティングにしてください!") # Agent that uses structured outputs structured_output_agent = Agent( model=OpenAIChat(id="gpt-5-mini"), description="あなたは映画の脚本を書きます。", output_schema=MovieScript, ) structured_output_agent.print_response("バブル期の東京") - サンプルを実行します。
ライブラリのインストール
pip install openai agnoキーのエクスポート
export OPENAI_API_KEY=xxxサンプルの実行
python movie_agent.py出力例
┏━ Message ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ ┃ バブル期の東京 ┃ ┃ ┃ ┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛ ┏━ Response (18.9s) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ ┃ { ┃ ┃ "setting": "1989年、バブル絶頂期の東京。高層ビルが次々と建設され、六本木や赤坂のディスコには毎晩人々が溢れ、誰もが明日への夢を語り合う、きら ┃ ┃ "ending": "バブルが崩壊し、ケンジは会社を辞め、美咲もクラブを去る。二人は小さなカフェを郊外に開き、質素だが心豊かな生活を始める。かつての派手 ┃ ┃ "genre": "ロマンティックコメディ", ┃ ┃ "name": "ネオン・ドリームズ 〜泡沫の約束〜", ┃ ┃ "characters": [ ┃ ┃ "桜井ケンジ - 証券会社の若手営業マン、野心家だが心優しい", ┃ ┃ "田中美咲 - 銀座の高級クラブのホステス、実は地方出身で夢を追っている", ┃ ┃ "山本太郎 - ケンジの先輩、バブルに踊らされる典型的なバブル紳士", ┃ ┃ "小林由美 - 美咲の同僚、現実的で地に足がついた性格", ┃ ┃ "エリック・トンプソン - アメリカから来た投資家、日本のバブル経済に魅了されている" ┃ ┃ ], ┃ ┃ "storyline": "証券会社で働くケンジは、接待で訪れた銀座の高級クラブで美咲と出会い、彼女の飾らない笑顔に心を奪われる。金と成功がすべてのバブル ┃ ┃ } ┃ ┃ ┃ ┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
出力は MovieScript クラスのオブジェクトです、以下のように見えます :
MovieScript( │ setting='In the bustling streets and iconic skyline of New York City.', │ ending='Isabella and Alex, having narrowly escaped the clutches of the Syndicate, find themselves standing at the top of the Empire State Building. As the glow of the setting sun bathes the city, they share a victorious kiss. Newly emboldened and as an unstoppable duo, they vow to keep NYC safe from any future threats.', │ genre='Action Thriller', │ name='The NYC Chronicles', │ characters=['Isabella Grant', 'Alex Chen', 'Marcus Kane', 'Detective Ellie Monroe', 'Victor Sinclair'], │ storyline='Isabella Grant, a fearless investigative journalist, uncovers a massive conspiracy involving a powerful syndicate plotting to control New York City. Teaming up with renegade cop Alex Chen, they must race against time to expose the culprits before the city descends into chaos. Dodging danger at every turn, they fight to protect the city they love from imminent destruction.' )
構造化出力のストリーミング
ストリーミングは output_schema と組み合わせて使用できます。これは、構造化出力をイベントストリーム内の単一の RunContent イベントとして返します。
- 構造化出力のストリーミングの例
streaming_agent.py
import asyncio from typing import Dict, List from agno.agent import Agent from agno.models.openai.chat import OpenAIChat from pydantic import BaseModel, Field class MovieScript(BaseModel): setting: str = Field( ..., description="大ヒット映画にふさわしい素敵な舞台を提供してください。" ) ending: str = Field( ..., description="映画のエンディング (結末)。それがない場合は、ハッピーエンドでお願いします。", ) genre: str = Field( ..., description="映画のジャンル。それがない場合は、アクション、スリラー、またはロマンティックコメディを選択してください。", ) name: str = Field(..., description="この映画に名前を付けてください") characters: List[str] = Field(..., description="この映画の登場人物たちの名前。") storyline: str = Field( ..., description="映画のストーリーの3センテンス(文)。エキサイティングにしてください!" ) rating: Dict[str, int] = Field( ..., description="映画に対するあなた自身の評価。1~10。キー 'story' と 'acting' を含む辞書を返します。", ) # Agent that uses structured outputs with streaming structured_output_agent = Agent( model=OpenAIChat(id="gpt-5-mini"), description="あなたは映画の脚本を書きます。", output_schema=MovieScript, ) structured_output_agent.print_response( "東京", stream=True, stream_intermediate_steps=True ) - サンプルを実行します。
ライブラリのインストール
pip install openai agnoキーのエクスポート
export OPENAI_API_KEY=xxxサンプルの実行
python streaming_agent.py出力例
┏━ Message ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ ┃ 東京 ┃ ┃ ┃ ┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛ ┏━ Response (17.2s) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ ┃ ┃ { ┃ ┃ "setting": "現代の東京。渋谷のスクランブル交差点、浅草の伝統的な街並み、お台場の夜景、そして隠れ家的な下北沢のカフェなど、東京の多彩な顔が物 ┃ ┃ "ending": "ハッピーエンド。一年後の春、満開の桜が舞う上野公園で、ユイとケンジは二人で花見をしている。ユイは転職して仕事とプライベートのバラン ┃ ┃ "genre": "ロマンティックコメディ", ┃ ┃ "name": "ネオン・ハート", ┃ ┃ "characters": [ ┃ ┃ "佐藤ユイ - 28歳の広告代理店勤務のキャリアウーマン", ┃ ┃ "田中ケンジ - 30歳の売れないマンガ家だが心優しい", ┃ ┃ "鈴木アヤ - ユイの親友で自由奔放なフリーランスカメラマン", ┃ ┃ "山田タカシ - ケンジの編集担当で厳しいが面倒見が良い" ┃ ┃ ], ┃ ┃ "storyline": "東京のど真ん中、渋谷のスクランブル交差点で偶然ぶつかった二人、ユイとケンジ。仕事に追われるユイと夢を追うケンジは正反対の人生を ┃ ┃ "rating": { ┃ ┃ "story": 8, ┃ ┃ "acting": 9 ┃ ┃ } ┃ ┃ } ┃ ┃ ┃ ┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
構造化入力
エージェントは構造化入力 (i.e pydantic model or TypedDict) を Agent.run() や Agent.print_response() で input パラメータとして渡すことでそれを提供できます。
- 構造化入力の例
from typing import List from agno.agent import Agent from agno.models.openai import OpenAIChat from agno.tools.hackernews import HackerNewsTools from pydantic import BaseModel, Field class ResearchTopic(BaseModel): """Structured research topic with specific requirements""" topic: str focus_areas: List[str] = Field(description="Specific areas to focus on") target_audience: str = Field(description="Who this research is for") sources_required: int = Field(description="Number of sources needed", default=5) hackernews_agent = Agent( name="Hackernews Agent", model=OpenAIChat(id="gpt-5-mini"), tools=[HackerNewsTools()], role="Extract key insights and content from Hackernews posts", ) hackernews_agent.print_response( input=ResearchTopic( topic="AI", focus_areas=["AI", "Machine Learning"], target_audience="Developers", sources_required=5, ) ) - サンプルを実行します。
ライブラリのインストール
pip install openai agnoキーのエクスポート
export OPENAI_API_KEY=xxxサンプルの実行
python structured_input_agent.py
入力の検証
エージェントで input_schema を設定することで入力を検証できます。入力を辞書として渡す場合、スキーマに対して自動的に検証されます。
- 入力検証の例
validating_input_agent.py
from typing import List from agno.agent import Agent from agno.models.openai import OpenAIChat from agno.tools.hackernews import HackerNewsTools from pydantic import BaseModel, Field class ResearchTopic(BaseModel): """Structured research topic with specific requirements""" topic: str focus_areas: List[str] = Field(description="Specific areas to focus on") target_audience: str = Field(description="Who this research is for") sources_required: int = Field(description="Number of sources needed", default=5) # Define agents hackernews_agent = Agent( name="Hackernews Agent", model=OpenAIChat(id="gpt-5-mini"), tools=[HackerNewsTools()], role="Extract key insights and content from Hackernews posts", input_schema=ResearchTopic, ) # Pass a dict that matches the input schema hackernews_agent.print_response( input={ "topic": "AI", "focus_areas": ["AI", "Machine Learning"], "target_audience": "Developers", "sources_required": "5", } ) - サンプルを実行します。
ライブラリのインストール
pip install openai agnoキーのエクスポート
export OPENAI_API_KEY=xxxサンプルの実行
python validating_input_agent.py
型安全なエージェント
input_schema と output_schema の両方を組み合わせて、end-to-end な型安全を備えた、型安全な (typesafe) エージェントを作成できます – 入力から出力まで完全に検証されたデータパイプラインです。
完全な型安全リサーチ・エージェント
リサーチ・タスクに対して完全に型安全なエージェントを示す包括的な例です :
- 型安全なリサーチ・エージェントの作成
typesafe_research_agent.py
from typing import List from agno.agent import Agent from agno.models.anthropic import Claude from agno.tools.hackernews import HackerNewsTools from pydantic import BaseModel, Field from rich.pretty import pprint # 入力スキーマの定義 class ResearchTopic(BaseModel): topic: str sources_required: int = Field(description="情報ソースの数", default=5) # 出力スキーマの定義 class ResearchOutput(BaseModel): summary: str = Field(..., description="調査のエグゼクティブ・サマリー") insights: List[str] = Field(..., description="記事から得られる重要な洞察") top_stories: List[str] = Field( ..., description="見つかった、最も関連性の高い人気の記事" ) technologies: List[str] = Field( ..., description="言及された技術" ) sources: List[str] = Field(..., description="最も関連性の高い記事へのリンク") # Define your agent hn_researcher_agent = Agent( # Model to use model=Claude(id="claude-haiku-4-5"), # Tools to use tools=[HackerNewsTools()], instructions="指定されたトピックに関する Hacker News の記事を調査する", # Add your input schema input_schema=ResearchTopic, # Add your output schema output_schema=ResearchOutput, ) # Run the Agent response = hn_researcher_agent.run( input=ResearchTopic(topic="AI", sources_required=5) ) # Print the response pprint(response.content) - サンプルを実行します。
ライブラリのインストール
pip install agno anthropicAPI キーの設定
export ANTHROPIC_API_KEY=xxxサンプルの実行
python typesafe_research_agent.py出力例
ResearchOutput( │ summary='Hacker News で最新の AI 関連の記事を調査しました。AI メモリ機能、大規模言語モデルの最適化、機械学習フレームワークの進化など、AI 技術の最新動向が多く報告されています。特に、Anthropic による Claude の メモリ機能、PyTorch の新しい技術、および言語モデルの高速化に関する研究が注目を集めています。', │ insights=[ │ │ 'Claude にメモリ機能が実装され、AI アシスタントがユーザーとの対話から情報を記憶・学習できるようになった', │ │ 'PyTorch Monarch は機械学習モデルのトレーニングと推論の効率化を実現している', │ │ 'Fast-DLLM は拡散言語モデルの高速化の新しいアプローチを提供し、トレーニング不要の加速を実現', │ │ 'Node ベースの UI フレームワーク (React Flow) が開発され、AI アプリケーション構築の利便性が向上', │ │ 'AI 関連の研究論文が頻繁に共有されており、学術的な進展が高い' │ ], │ top_stories=[ │ │ 'Claude Memory - Anthropic による AI アシスタント向けメモリ機能の導入 (414 points)', │ │ 'PyTorch Monarch - 機械学習フレームワークの最適化技術 (327 points)', │ │ '/dev/null is an ACID compliant database - データベース設計に関するユニークな解釈 (242 points)', │ │ 'React Flow, open source libraries for node-based UIs - AI UI 開発ツール (93 points)', │ │ 'Fast-DLLM: Training-Free Acceleration of Diffusion LLM - 言語モデル高速化研究' │ ], │ technologies=[ │ │ 'Claude AI', │ │ 'PyTorch', │ │ 'Diffusion Language Models (DLLM)', │ │ 'React Flow', │ │ 'Anthropic API', │ │ 'Node-based UI', │ │ 'Machine Learning Frameworks', │ │ 'Memory Systems for AI' │ ], │ sources=[ │ │ 'https://www.anthropic.com/news/memory', │ │ 'https://pytorch.org/blog/introducing-pytorch-monarch/', │ │ 'https://arxiv.org/abs/2505.22618', │ │ 'https://github.com/xyflow/xyflow', │ │ 'https://jyu.dev/blog/why-dev-null-is-an-acid-compliant-database/' │ ] )
以上