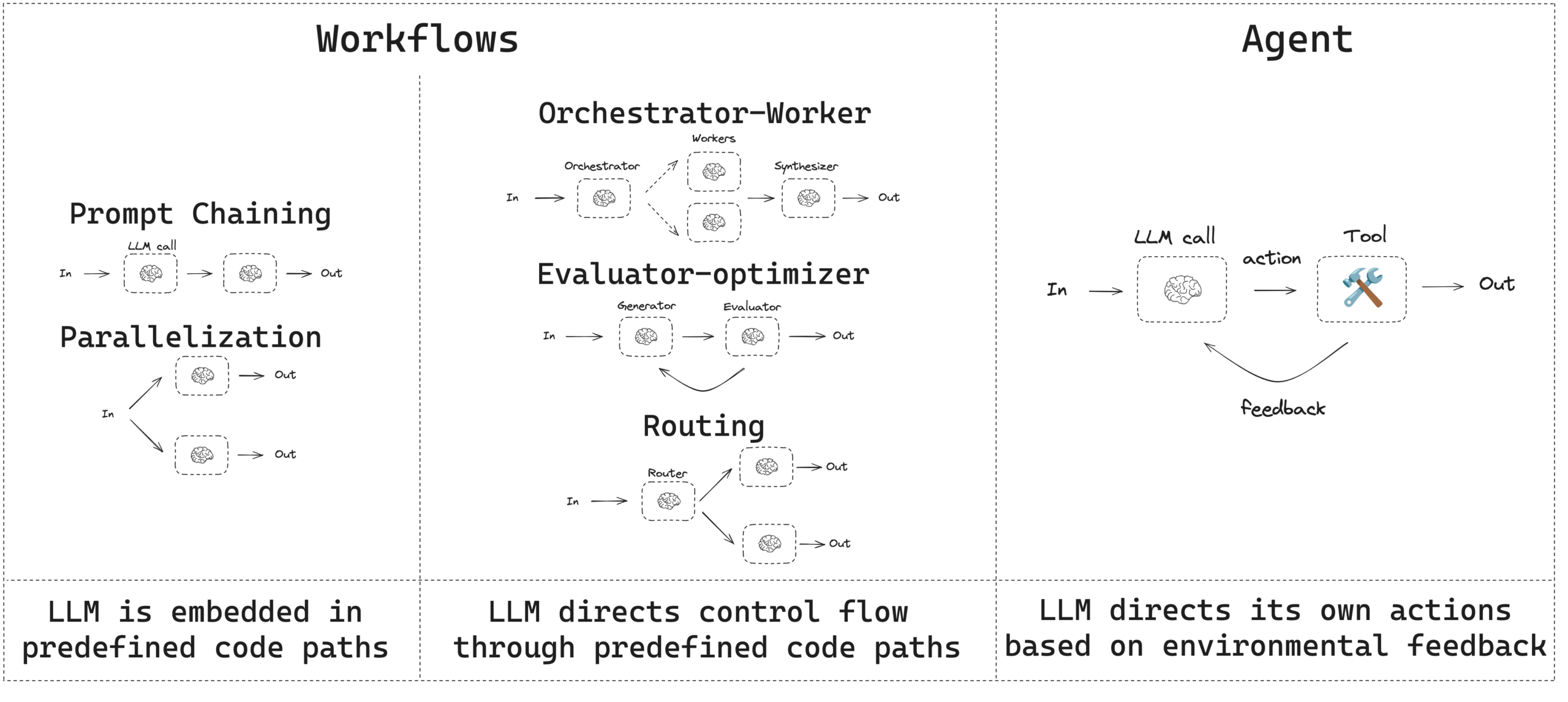
このガイドは一般的なワークフローとエージェントのパターンを説明します。ワークフロー には事前決定されたコード・パスがあり、特定の順序で動作するように設計されています。エージェント は動的で、独自の処理とツールの使用方法を定義します。
LangGraph 1.0 alpha : Get started – ワークフローとエージェント
作成 : クラスキャット・セールスインフォメーション
作成日時 : 10/01/2025
バージョン : 1.0.0a4
* 本記事は docs.langchain.com の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています。スニペットはできる限り日本語を使用しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
LangGraph 1.0 alpha : Get started – ワークフローとエージェント
このガイドは一般的なワークフローとエージェントのパターンをレビューします。
- ワークフローには事前決定されたコード・パスがあり、特定の順序で動作するように設計されています。
- エージェントは動的で、独自の処理とツールの使用方法を定義します。
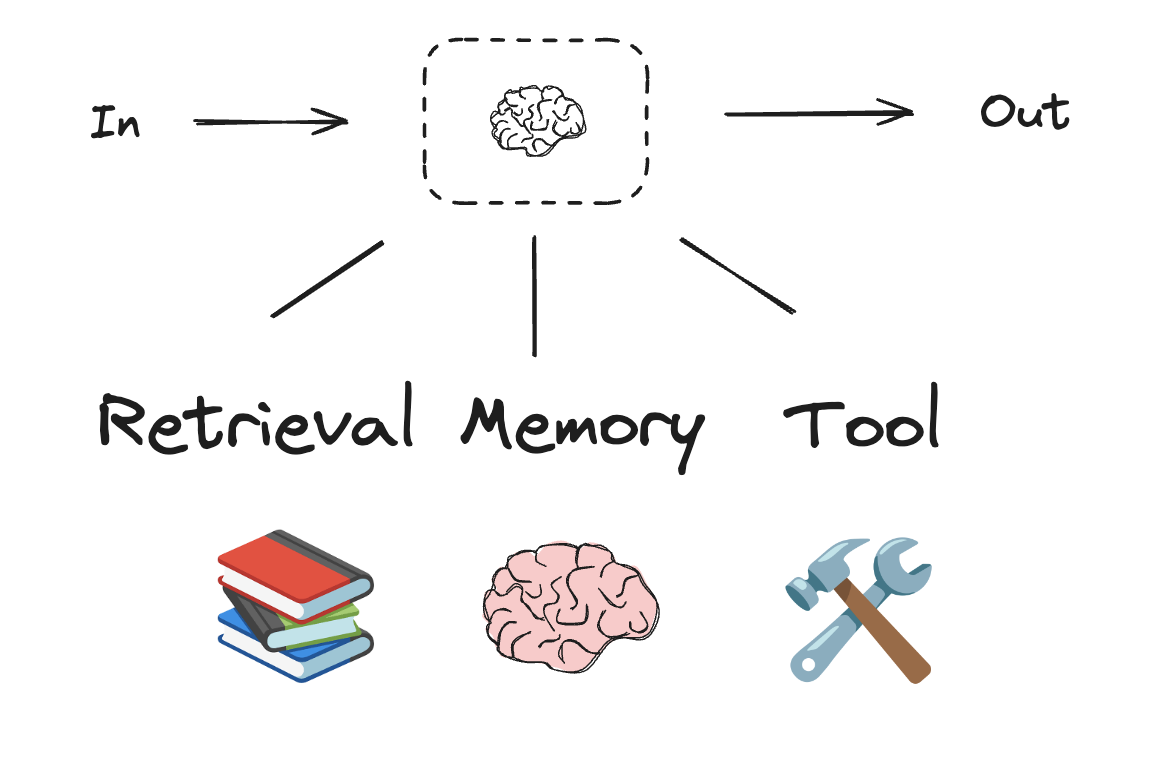
エージェントとワークフローを構築する際、LangGraph は 永続性、ストリーミング そしてデバッグと 配備 のサポートを含む、様々な利点を提供します。
セットアップ
ワークフローやエージェントを構築するには、構造化出力とツール呼び出しをサポートする 任意のチャットモデル を使用できます。以下の例は Anthropic を使用しています :
- 依存関係のインストール :
pip install langchain_core langchain-anthropic langgraph - LLM の初期化 :
import os import getpass from langchain_anthropic import ChatAnthropic def _set_env(var: str): if not os.environ.get(var): os.environ[var] = getpass.getpass(f"{var}: ") _set_env("ANTHROPIC_API_KEY") llm = ChatAnthropic(model="claude-3-5-sonnet-latest")
LLM と拡張
ワークフローとエージェント型システムは LLM とそれらに追加する様々な拡張に基づいています。ツール呼び出し、構造化出力、そして 短期メモリ は LLM をニーズに合わせてカスタマイズするためのオプションです。
# Schema for structured output
from pydantic import BaseModel, Field
class SearchQuery(BaseModel):
search_query: str = Field(None, description="Query that is optimized web search.")
justification: str = Field(
None, description="Why this query is relevant to the user's request."
)
# Augment the LLM with schema for structured output
structured_llm = llm.with_structured_output(SearchQuery)
# Invoke the augmented LLM
output = structured_llm.invoke("How does Calcium CT score relate to high cholesterol?")
# Define a tool
def multiply(a: int, b: int) -> int:
return a * b
# Augment the LLM with tools
llm_with_tools = llm.bind_tools([multiply])
# Invoke the LLM with input that triggers the tool call
msg = llm_with_tools.invoke("What is 2 times 3?")
# Get the tool call
msg.tool_calls
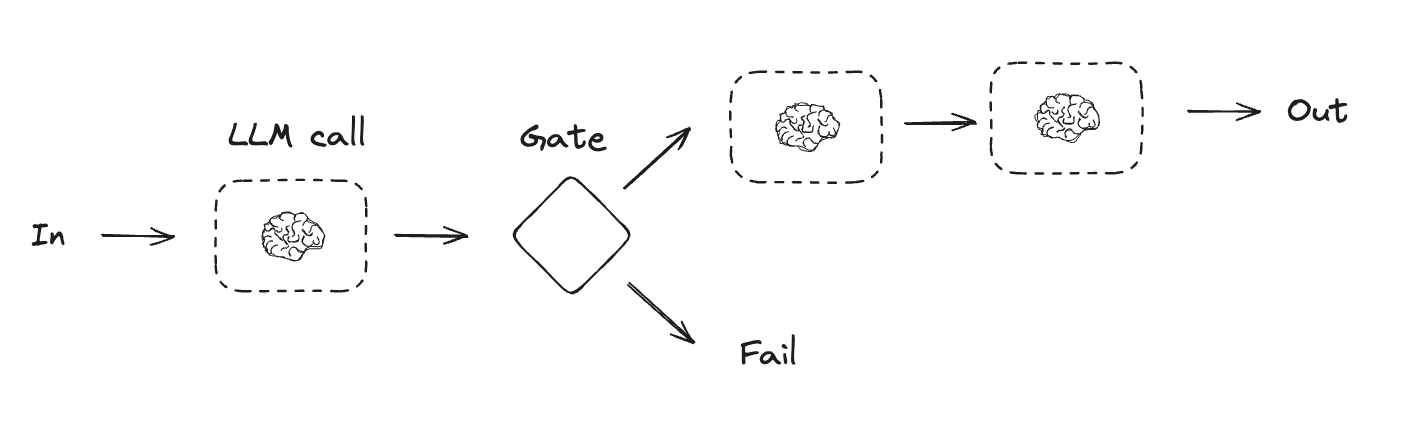
プロンプト連鎖 (chaining)
プロンプト連鎖は、各 LLM 呼び出しが前の呼び出しの出力を処理することです。それは、より小さく検証可能なステップに分解できる、明確に定義されたタスクを実行するために使用される場合が多いです。例として :
- ドキュメントを様々な言語に翻訳する
- 生成されたコンテンツの一貫性を検証する
Graph API
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# グラフ状態
class State(TypedDict):
topic: str
joke: str
improved_joke: str
final_joke: str
# ノード
def generate_joke(state: State):
"""最初の LLM 呼び出し: 最初のジョークを生成"""
msg = llm.invoke(f"{state['topic']} について短いジョークを書いてください")
return {"joke": msg.content}
def check_punchline(state: State):
"""ゲート関数: ジョークにオチ (punchline) があるかどうかを確認する"""
# 簡単なチェック - ジョークに「?」または「!」が含まれているか?
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass"
return "Fail"
def improve_joke(state: State):
"""2 回目の LLM 呼び出し: ジョークの改良"""
msg = llm.invoke(f"言葉遊び (wordplay) を加えて次のジョークをもっと面白くしてください: {state['joke']}")
return {"improved_joke": msg.content}
def polish_joke(state: State):
"""3 回目の LLM 呼び出し: 最終的な仕上げ"""
msg = llm.invoke(f"次のジョークに意外なひねりを加えます: {state['improved_joke']}")
return {"final_joke": msg.content}
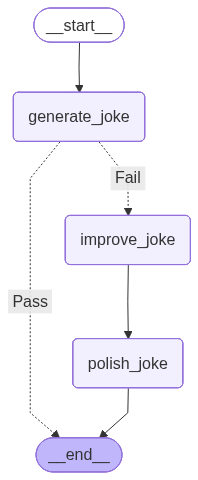
# ワークフローの構築
workflow = StateGraph(State)
# ノードの追加
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_node("polish_joke", polish_joke)
# ノードを接続するためのエッジを追加
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", "polish_joke")
workflow.add_edge("polish_joke", END)
# コンパイル
chain = workflow.compile()
# ワークフローの表示
display(Image(chain.get_graph().draw_mermaid_png()))
# Invoke
state = chain.invoke({"topic": "猫"})
print("最初のジョーク:")
print(state["joke"])
print("\n--- --- ---\n")
if "improved_joke" in state:
print("改良されたジョーク:")
print(state["improved_joke"])
print("\n--- --- ---\n")
print("最終的なジョーク:")
print(state["final_joke"])
else:
print("Joke failed quality gate - no punchline detected!")
出力例
最初のジョーク: はい、いくつかの猫に関する短いジョークをご紹介します: 1. 飼い主:「うちの猫は数学が得意なんです」 友達:「へぇ、すごいね!どんなことができるの?」 飼い主:「引き算が特に上手なんです。いつも私の魚から半分引いていきます」 2. なぜ猫はインターネットが嫌いなの? ネズミがワイヤレスだから! 3. 猫:「私の人生の目標は世界征服よ」 犬:「すごいね!どうやって?」 猫:「まずは、この家のソファーを完全支配するところから始めるわ」 4. 飼い主:「うちの猫、最近ベジタリアンになったの」 友達:「へぇ、珍しいね」 飼い主:「ううん、単に観葉植物を食べ始めただけ...」 --- --- --- 改良されたジョーク: はい、言葉遊びを加えてみました: 1. 飼い主:「うちの猫は数学が得意なニャンです」 友達:「へぇ、すごいね!どんなことができるの?」 飼い主:「引き算が特に上手なんです。いつも私の魚から半分引いていきます。まさに引き算の天才ニャンです!」 2. なぜ猫はインターネットが嫌いなの? マウスがワイヤレスだし、キャッチできないから! (mouse=ネズミ/マウス、catch=捕まえる/接続する の掛け言葉) 3. 猫:「私の人生の目標は世界征服ニャ」 犬:「すごいワン!どうやって?」 猫:「まずは、この家のソファーを完全支配するところからニャ。それが私の野望ニャのだ!」 4. 飼い主:「うちの猫、最近ベジタリアンになったの」 友達:「へぇ、珍しいニャ」 飼い主:「ううん、単に観葉植物を食べ始めただけ...キャットニップ以外は見向きもしニャいけど」 それぞれに「ニャン/ニャ」や「ワン」などの擬音語を活用し、また2番目では「マウス」の二重の意味を使って言葉遊びを加えてみました。 --- --- --- 最終的なジョーク: ジョークにさらに面白いひねりを加えてみましょう: 1. 飼い主:「うちの猫は数学が得意なニャンです」 友達:「へぇ、すごいね!どんなことができるの?」 飼い主:「引き算が特に上手なんです。いつも私の魚から半分引いていきます」 友達:「それって...ただの泥棒ニャンじゃ...」 飼い主:「いいえ、経済学も学んでるんです。魚の需要と供給の法則を実践してるんですニャ!」 2. なぜ猫はプログラマーになれないの? キーボードで「Ctrl+C」をしようとすると、 いつも本能で「Cat+C(キャット・アンド・チェイス)」になっちゃうニャン! 3. 猫:「私の人生の目標は世界征服ニャ」 犬:「すごいワン!どうやって?」 猫:「まずは、この家のソファーを完全支配するところからニャ」 犬:「それって...既に達成してるよニャ」 猫:「あ!そうだニャ...じゃあ次は冷蔵庫かニャ!」 4. 飼い主:「うちの猫、最近ヨガを始めたの」 友達:「へぇ、どんなポーズができるの?」 飼い主:「寝ながらできる『ダウニャード・キャット』が得意みたい...」 友達:「それ...ただの昼寝じゃ...」 より複雑な言葉遊びや、予想外の展開を加えることで、ユーモアを強化してみました。
Functional API
from langgraph.func import entrypoint, task
# タスク
@task
def generate_joke(topic: str):
"""最初の LLM 呼び出し: 最初のジョークを生成"""
msg = llm.invoke(f"{topic} について短いジョークを1つ書いてください")
return msg.content
def check_punchline(joke: str):
"""ゲート関数: ジョークにオチ (punchline) があるかどうかを確認する"""
# 簡単なチェック - ジョークに「?」または「!」が含まれているか?
if "?" in joke or "!" in joke:
return "Pass"
return "Fail"
@task
def improve_joke(joke: str):
"""2 回目の LLM 呼び出し: ジョークの改良"""
msg = llm.invoke(f"言葉遊び (wordplay) を加えて次のジョークをもっと面白くしてください: {joke}")
return msg.content
@task
def polish_joke(joke: str):
"""3 回目の LLM 呼び出し: 最終的な仕上げ"""
msg = llm.invoke(f"次のジョークに意外なひねりを加えます: {joke}")
return msg.content
#ワークフロー
@entrypoint()
def prompt_chaining_workflow(topic: str):
original_joke = generate_joke(topic).result()
if check_punchline(original_joke) == "Pass":
return original_joke
improved_joke = improve_joke(original_joke).result()
return polish_joke(improved_joke).result()
# Invoke
# そのまま表示すると辞書のリストなので、バッファに溜める
buffer = []
for step in prompt_chaining_workflow.stream("犬", stream_mode="updates"):
buffer.append(step)
#print(step)
#print("\n")
#for step in buffer:
# print(step)
# print("\n")
print(buffer[0]['generate_joke'])
print(buffer[1]['improve_joke'])
print(buffer[2]['polish_joke'])
print(buffer[3]['prompt_chaining_workflow'])
出力例
犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「先にあなたがやってみせてください」と答えました。 いくつかの言葉遊びを加えたバージョンを提案します: 1. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「イヌ(居ぬ)ままに命令されても困りますよ。先にあなたがやってみせてください」と答えました。 2. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「ワン(私)だけにそんな命令しないでください。先にあなたがやってみせてください」と答えました。 3. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「イヌ(以温)々に命令されても困ります。先にあなたがやってみせてください」と答えました。 これらのバージョンでは「イヌ/犬」や「ワン」という言葉を活かした掛け言葉を使用して、ユーモアを付け加えています。 面白い提案をありがとうございます!さらにいくつかのひねりを加えたバージョンを提案させていただきます: 4. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「ケン(犬/権)利の侵害です!先にあなたがやってみせてください」と答えました。 5. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「パピー(puppy/はっぴー)じゃないですね。先にあなたがやってみせてください」と答えました。 6. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「タイ(耐)えられない命令ですね。先にあなたがやってみせてください」と答えました。 これらのバージョンでは: - 「犬/権」の掛け言葉 - 「puppy/happy」の音の類似性 - 「待つ/耐える」の掛け言葉 を使って、さらなるユーモアを加えてみました。 面白い提案をありがとうございます!さらにいくつかのひねりを加えたバージョンを提案させていただきます: 4. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「ケン(犬/権)利の侵害です!先にあなたがやってみせてください」と答えました。 5. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「パピー(puppy/はっぴー)じゃないですね。先にあなたがやってみせてください」と答えました。 6. 犬の散歩中に飼い主が「おすわり」と命令しました。 するとワンちゃんは「タイ(耐)えられない命令ですね。先にあなたがやってみせてください」と答えました。 これらのバージョンでは: - 「犬/権」の掛け言葉 - 「puppy/happy」の音の類似性 - 「待つ/耐える」の掛け言葉 を使って、さらなるユーモアを加えてみました
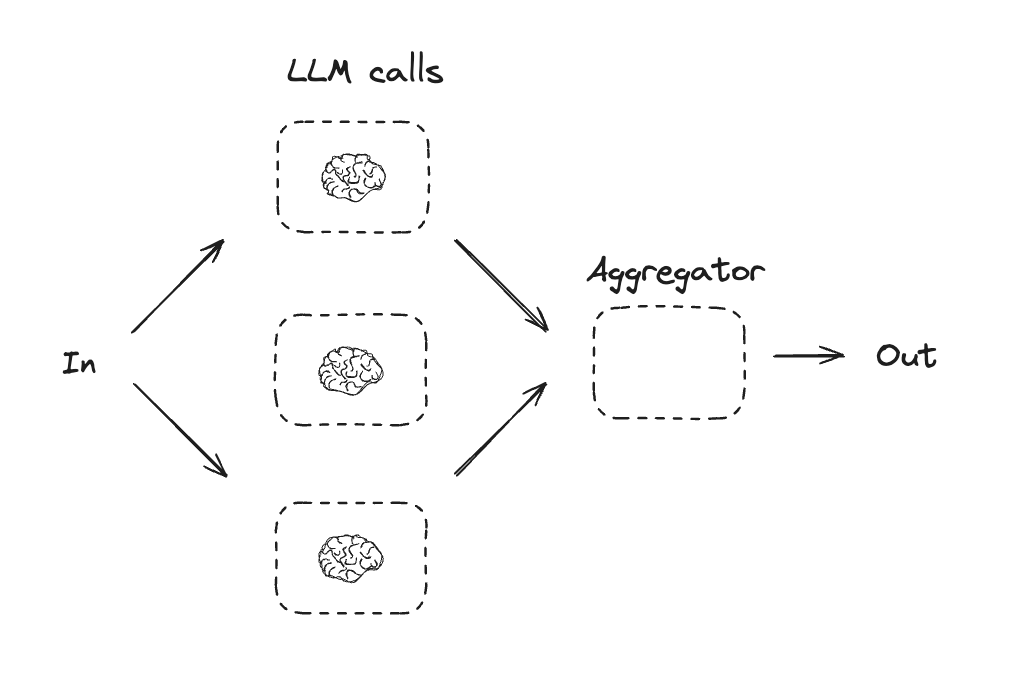
並列化
並列化では、LLM はタスクを同時に処理します。これは、複数の独立したサブタスクを同時に実行するか、異なる出力を確認するために同じタスクを複数回実行することで実現されます。並列化は一般には以下の目的で使用されます :
- サブタスクを分割して並列で実行することで、速度を向上させます。
- タスクを複数回実行して異なる出力を確認します、これは信頼性を向上させます。
例として :
- ドキュメントのキーワードを処理するサブタスクを実行し、フォーマットエラーをチェックする 2 番目のサブタスクを実行する。
- 引用数、使用されているソースの数、ソースの品質のような、様々な基準に基づいてドキュメントの精度をスコアリングするタスクを複数回実行する。
Graph API
%pip install -q langchain_core langchain-anthropic langgraph
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# グラフ状態
class State(TypedDict):
topic: str
joke: str
story: str
poem: str
combined_output: str
# ノード
def call_llm_1(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"{state['topic']} についてのジョークを書いてください")
return {"joke": msg.content}
def call_llm_2(state: State):
"""Second LLM call to generate story"""
msg = llm.invoke(f"Write a story about {state['topic']} についてのストーリーを書いてください")
return {"story": msg.content}
def call_llm_3(state: State):
"""Third LLM call to generate poem"""
msg = llm.invoke(f"{state['topic']} についての詩を書いてください")
return {"poem": msg.content}
def aggregator(state: State):
"""ジョークとストーリーを1つの出力に組み合わせる"""
combined = f"{state['topic']} についてのストーリー、ジョーク、詩があります!\n\n"
combined += f"ストーリー:\n{state['story']}\n\n"
combined += f"ジョーク:\n{state['joke']}\n\n"
combined += f"詩:\n{state['poem']}"
return {"combined_output": combined}
# ワークフローの構築
parallel_builder = StateGraph(State)
# ノードの追加
parallel_builder.add_node("call_llm_1", call_llm_1)
parallel_builder.add_node("call_llm_2", call_llm_2)
parallel_builder.add_node("call_llm_3", call_llm_3)
parallel_builder.add_node("aggregator", aggregator)
# ノードを接続するエッジの追加
parallel_builder.add_edge(START, "call_llm_1")
parallel_builder.add_edge(START, "call_llm_2")
parallel_builder.add_edge(START, "call_llm_3")
parallel_builder.add_edge("call_llm_1", "aggregator")
parallel_builder.add_edge("call_llm_2", "aggregator")
parallel_builder.add_edge("call_llm_3", "aggregator")
parallel_builder.add_edge("aggregator", END)
parallel_workflow = parallel_builder.compile()
# Invoke
state = parallel_workflow.invoke({"topic": "紅葉"})
print(state["combined_output"])
出力例
紅葉 についてのストーリー、ジョーク、詩があります! ストーリー: 「秋の約束」 清々しい秋風が吹く10月のある日、私は祖母と一緒に山へ紅葉狩りに出かけることになりました。 祖母は私が小さい頃から、毎年この時期になると紅葉を見に連れて行ってくれていました。今年は私が大学を卒業して就職する最後の年。特別な思いを込めて、懐かしい山道を歩くことにしたのです。 山道を登っていくと、まるで絵筆でさっと描いたような鮮やかな赤や黄色の葉が、私たちを出迎えてくれました。イロハモミジは深い赤に染まり、カエデの葉は優しい黄金色に輝いています。 「あら、覚えてる?」と祖母が言いました。「小さい頃、あなたはここで落ち葉を集めては、宝物だって言って持って帰ろうとしたのよ」 私は懐かしく笑いました。確かに、色とりどりの紅葉は子供の目には宝石のように見えたものです。 山頂に着くと、眼下に広がる紅葉の絨毯に息を呑みました。赤や黄色、オレンジ色が溶け合って、まるで大地が燃えているかのような壮大な景色でした。 「来年も、また一緒に来ようね」 祖母がそっと私の手を握りました。 「うん、約束だよ」 私は微笑んで答えました。 夕暮れ時、下山する私たちの足元には、優しく舞い落ちる紅葉の葉。その一枚一枚に、これまでの思い出と、これからの約束が刻まれているようでした。 人生の節目に立つ私に、紅葉は変化の美しさと、続いていく大切な絆を教えてくれました。来年も、その次の年も、きっとここで新しい季節の色を見つけられることでしょう。 終わり ジョーク: 紅葉にまつわる面白いジョークをいくつかご紹介します: 1. 「紅葉狩りに行った友達が帰ってこない...」 「きっと葉っぱと一緒に散ってしまったんだね」 2. 「紅葉の木に聞いてみた:どうして赤くなってるの?」 「恥ずかしくて...」 3. 「紅葉は何色が好き?」 「もみじ(もう見じ)らんな!」 4. 「なぜ紅葉は写真を撮られるのが得意?」 「いつも色んなポーズを葉してるから!」 5. 「紅葉の木々が集まる会議は?」 「もみじ会(理事会)!」 6. 「紅葉の木が転んだ!」 「大丈夫、落ち葉でクッションになったよ」 これらは少し親父ギャグっぽいですが、季節を楽しむユーモアとして使えるかもしれません! 詩: 紅葉をテーマにした詩を2つ作ってみました: 『秋の色絵』 山々を染める 朱に黄に橙に 風に揺られ 舞い落ちる葉は 自然の絵筆 『もみじ狩り』 清らかな 山の空気に 包まれて 足元に広がる 錦の絨毯 刻一刻と 移りゆく陽に 輝きを増す 秋の贈り物 これらの詩は、紅葉の美しさや自然の移ろいを表現しようと試みました。紅葉の色彩の豊かさ、季節の変化、そして人々に与える心の安らぎを詠んでいます。
Functional API
%pip install -q langchain_core langchain-anthropic langgraph
from langgraph.func import entrypoint, task
@task
def call_llm_1(topic: str):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"{topic} についてのジョークを書いてください")
return msg.content
@task
def call_llm_2(topic: str):
"""Second LLM call to generate story"""
msg = llm.invoke(f"{topic} についてのストーリーを書いてください")
return msg.content
@task
def call_llm_3(topic):
"""Third LLM call to generate poem"""
msg = llm.invoke(f"{topic} についての詩を書いてください")
return msg.content
@task
def aggregator(topic, joke, story, poem):
"""Combine the joke and story into a single output"""
combined = f"{topic} についてのストーリー、ジョーク、詩があります!\n\n"
combined += f"ストーリー:\n{story}\n\n"
combined += f"ジョーク:\n{joke}\n\n"
combined += f"詩:\n{poem}"
return combined
# ワークフローの構築
@entrypoint()
def parallel_workflow(topic: str):
joke_fut = call_llm_1(topic)
story_fut = call_llm_2(topic)
poem_fut = call_llm_3(topic)
return aggregator(
topic, joke_fut.result(), story_fut.result(), poem_fut.result()
).result()
buffer = []
for step in parallel_workflow.stream("犬", stream_mode="updates"):
buffer.append(step)
print(buffer[4]['parallel_workflow'])
出力例
犬 についてのストーリー、ジョーク、詩があります! ストーリー: 「忠犬ポチ」 寒い冬の夜、私の家に一匹の子犬が迷い込んできました。小さな体は震え、目は不安げでした。家族で相談し、この子犬を飼うことに決めました。名前はポチに決まりました。 ポチは驚くほど賢い犬でした。毎朝、私が目覚まし時計より先に起こしてくれ、新聞も取ってきてくれました。散歩の時は必ず紐を咥えて待っていて、道中も決して暴れることはありませんでした。 特に印象に残っているのは、ある雨の日のことです。祖母が具合を悪くして倒れた時、ポチは近所に住む叔母の家まで走って行き、助けを呼んできてくれました。その機転の利いた行動のおかげで、祖母は早期に治療を受けることができました。 ポチは私たち家族の一員として15年間を共に過ごしました。最期まで忠実で優しい犬でした。今でも写真を見るたびに、あの温かな目と柔らかな毛並みを思い出します。 ポチは単なるペットではなく、本当の家族でした。犬は人間の最高の友達だということを、身をもって教えてくれました。今でも私たち家族の心の中で、ポチは生き続けています。 この経験から、動物たちの優しさと忠誠心、そして家族の絆の大切さを学びました。ポチとの思い出は、私の人生で最も大切な宝物の一つとなっています。 ジョーク: はい、犬に関する面白いジョークをいくつか紹介します: 1. Q: 犬が銀行に行く理由は? A: 口座を開きたいワン! 2. Q: 犬が好きな野菜は? A: ワンダフルーツ! 3. Q: 犬のお医者さんを何と呼ぶ? A: わんわん科医! 4. Q: 犬が一番好きな季節は? A: 春だワン!(散歩ワン!) 5. Q: なぜ犬はしっぽを振るの? A: だって体全体を振るのは大変だからワン! 6. Q: 犬が写真を撮る時に言うことは? A: ワン、ツー、スリー! 7. Q: 犬の好きな映画は? A: ロッキーマウンテン(ロッキーまうんちん) これらは「ワン」という犬の鳴き声を活かした言葉遊びが多いですね。 詩: はい、犬についての詩を書かせていただきます。 「忠実な友」 まっすぐな瞳で 私を見つめる 尻尾を振って 喜びを表す どんな時でも そばにいてくれる かけがえのない 家族の一員 小さな手のひらを 優しく舐める 散歩の時間を 心待ちにして 私の悲しみも 全て受け止め 無条件の愛を 教えてくれる もふもふの毛を なでると安らぐ 温かな息遣い 心地よい存在 言葉はなくても 気持ちが通じ合う 最高の親友 私の大切な犬 この詩は、犬との暮らしの中で感じる愛情や絆、そして犬が私たちに与えてくれる幸せな気持ちを表現しようと試みました。
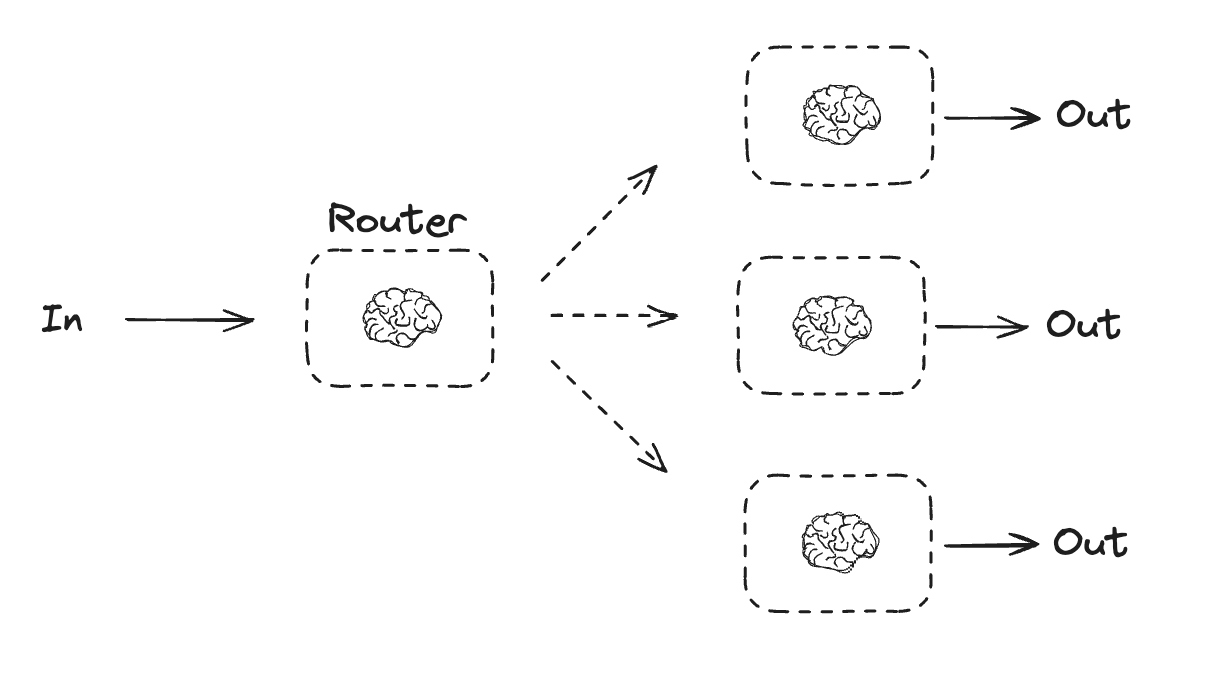
ルーティング
ルーティング・ワークフローは入力を処理してから、それらをコンテキスト固有のタスクに振り分けます。これは複雑なタスクに特化したフローを定義することを可能にします。例えば、製品に関連する質問に答えるために構築されたワークフローは、最初に質問の種類を処理してから、価格、返金、返品のための特定のプロセスにリクエストをルーティングするかもしれません。
Graph API
%pip install -q langchain_core langchain-anthropic langgraph
from pydantic import BaseModel, Field
from typing_extensions import TypedDict, Literal
from langgraph.graph import StateGraph, START, END
from langchain_core.messages import HumanMessage, SystemMessage
from IPython.display import Image, display
# ルーティングロジックとして使用する構造化出力のスキーマ
class Route(BaseModel):
step: Literal["詩", "ストーリー", "ジョーク"] = Field(
None, description="ルーティング・プロセスの次のステップ"
)
# 構造化出力のスキーマにより LLM の拡張
router = llm.with_structured_output(Route)
# 状態
class State(TypedDict):
input: str
decision: str
output: str
# ノード
def llm_call_1(state: State):
"""Write a story"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_2(state: State):
"""Write a joke"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_3(state: State):
"""Write a poem"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_router(state: State):
"""Route the input to the appropriate node"""
# Run the augmented LLM with structured output to serve as routing logic
decision = router.invoke(
[
SystemMessage(
content="ユーザーのリクエストに基づいて、入力をストーリー、ジョーク、または詩にルーティングします。"
),
HumanMessage(content=state["input"]),
]
)
return {"decision": decision.step}
# Conditional edge function to route to the appropriate node
def route_decision(state: State):
# Return the node name you want to visit next
if state["decision"] == "ストーリー":
return "llm_call_1"
elif state["decision"] == "ジョーク":
return "llm_call_2"
elif state["decision"] == "詩":
return "llm_call_3"
# ワークフローの構築
router_builder = StateGraph(State)
# ノードの追加
router_builder.add_node("llm_call_1", llm_call_1)
router_builder.add_node("llm_call_2", llm_call_2)
router_builder.add_node("llm_call_3", llm_call_3)
router_builder.add_node("llm_call_router", llm_call_router)
# ノード接続のためにエッジを追加
router_builder.add_edge(START, "llm_call_router")
router_builder.add_conditional_edges(
"llm_call_router",
route_decision,
{ # Name returned by route_decision : Name of next node to visit
"llm_call_1": "llm_call_1",
"llm_call_2": "llm_call_2",
"llm_call_3": "llm_call_3",
},
)
router_builder.add_edge("llm_call_1", END)
router_builder.add_edge("llm_call_2", END)
router_builder.add_edge("llm_call_3", END)
# ワークフローのコンパイル
router_workflow = router_builder.compile()
# ワークフローの表示
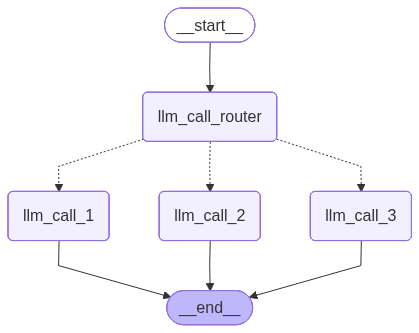
display(Image(router_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = router_workflow.invoke({"input": "猫についてジョークを書いてください"})
print(state["output"])
出力例
# 猫のジョーク集 🐱 **1. 猫の履歴書** - 職歴:飼い主の監視(24時間体制) - 特技:3秒前まで寝ていたのに、缶詰の音だけは聞き逃さない - 趣味:飼い主の大事な書類の上で寝ること **2. 猫の一日** ``` 午前3時:大運動会開催 午前6時:飼い主の顔面を踏みつけて起床要求 午前7時〜午後11時:睡眠 午後11時59分:突然の覚醒 ``` **3. 猫の論理** - 箱があったら入る - 高価なベッド < 段ボール箱 - 飼い主が忙しい時ほどかまってほしい - ドアは開いていても閉まっていてもダメ **4. 猫と犬の違い** - 犬:「この人は餌をくれる。この人は神様に違いない!」 - 猫:「この人は餌をくれる。私は神様に違いない!」 **5. 猫の本音** 「撫でて」→撫でる→「なんで触るの!?」 (猫あるあるです😸)
Functional API
%pip install -q langchain_core langchain-anthropic langgraph
from typing_extensions import Literal
from pydantic import BaseModel, Field
from langgraph.func import entrypoint, task
from langchain_core.messages import HumanMessage, SystemMessage
# Schema for structured output to use as routing logic
class Route(BaseModel):
step: Literal["詩", "ストーリー", "ジョーク"] = Field(
None, description="ルーティング・プロセスの次のステップ"
)
# Augment the LLM with schema for structured output
router = llm.with_structured_output(Route)
@task
def llm_call_1(input_: str):
"""Write a story"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_2(input_: str):
"""Write a joke"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_3(input_: str):
"""Write a poem"""
result = llm.invoke(input_)
return result.content
def llm_call_router(input_: str):
"""Route the input to the appropriate node"""
# Run the augmented LLM with structured output to serve as routing logic
decision = router.invoke(
[
SystemMessage(
content="ユーザーのリクエストに基づいて、入力をストーリー、ジョーク、または詩にルーティングします。"
),
HumanMessage(content=input_),
]
)
return decision.step
# ワークフローの作成
@entrypoint()
def router_workflow(input_: str):
next_step = llm_call_router(input_)
if next_step == "ストーリー":
llm_call = llm_call_1
elif next_step == "ジョーク":
llm_call = llm_call_2
elif next_step == "詩":
llm_call = llm_call_3
return llm_call(input_).result()
buffer = []
for step in router_workflow.stream("犬について詩を書いてください", stream_mode="updates"):
buffer.append(step)
print(buffer[1]['router_workflow'])
出力例
# 犬 四本の足で駆けてくる 尾を振って迎えてくれる 君の瞳は澄んでいて 嘘をつくことを知らない 雨の日も風の日も いつも傍にいてくれた 何も言わずに寄り添って 温かな鼻先を押し付ける 散歩の道は毎日同じでも 君にとっては冒険で 草むらの匂いを確かめて 小さな発見を喜ぶ ただ愛することだけを知り ただ信じることだけを知る 君は僕の最良の友 永遠に忘れない宝物
以上