Agno エージェントは、テキスト、画像、音声と動画の入力をサポートし、テキスト、画像、音声と動画の出力を生成することができます。
Agno : ユーザガイド : コンセプト : エージェント – マルチモーダル・エージェント
作成 : クラスキャット・セールスインフォメーション
作成日時 : 07/20/2025
バージョン : Agno 1.7.4
* 本記事は docs.agno.com の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
Agno ユーザガイド : コンセプト : エージェント – マルチモーダル・エージェント
Agno エージェントは、テキスト、画像、音声と動画の入力をサポートし、テキスト、画像、音声と動画の出力を生成することができます。For a complete overview, please checkout the compatibility matrix.
エージェントへのマルチモーダル入力
画像を理解し、必要に応じてツールを呼び出せるエージェントを作成しましょう
画像エージェント
image_agent.py
from agno.agent import Agent
from agno.media import Image
from agno.models.openai import OpenAIChat
from agno.tools.duckduckgo import DuckDuckGoTools
agent = Agent(
model=OpenAIChat(id="gpt-4o"),
tools=[DuckDuckGoTools()],
markdown=True,
)
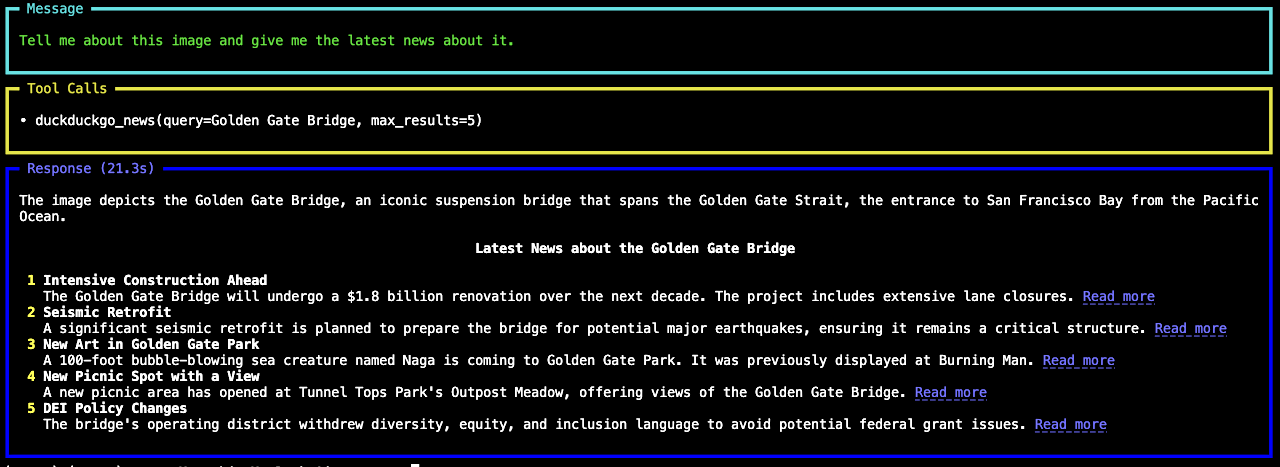
agent.print_response(
"Tell me about this image and give me the latest news about it.",
images=[
Image(
url="https://upload.wikimedia.org/wikipedia/commons/0/0c/GoldenGateBridge-001.jpg"
)
],
stream=True,
)
エージェントの実行 :
python image_agent.py
画像と同様に、入力として音声や動画も使用できます。
音声エージェント
audio_agent.py
import base64
import requests
from agno.agent import Agent, RunResponse # noqa
from agno.media import Audio
from agno.models.openai import OpenAIChat
# Fetch the audio file and convert it to a base64 encoded string
url = "https://openaiassets.blob.core.windows.net/$web/API/docs/audio/alloy.wav"
response = requests.get(url)
response.raise_for_status()
wav_data = response.content
agent = Agent(
model=OpenAIChat(id="gpt-4o-audio-preview", modalities=["text"]),
markdown=True,
)
agent.print_response(
"What is in this audio?", audio=[Audio(content=wav_data, format="wav")]
)
┃ The audio describes a simple fact about the movement of the sun, noting that the sun rises in the east and sets in the west. It also mentions that humans ┃ ┃ have observed this fact for thousands of years.
エージェントからのマルチモーダル出力
マルチモーダル入力を提供するのと同様に、エージェントからマルチモーダル出力を取得することもできます。
画像生成
以下の例は、エージェントで DALL-E を使用して画像を生成する方法を実演します。
image_agent2.py
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.tools.dalle import DalleTools
image_agent = Agent(
model=OpenAIChat(id="gpt-4o"),
tools=[DalleTools()],
description="You are an AI agent that can generate images using DALL-E.",
instructions="When the user asks you to create an image, use the `create_image` tool to create the image.",
markdown=True,
show_tool_calls=True,
)
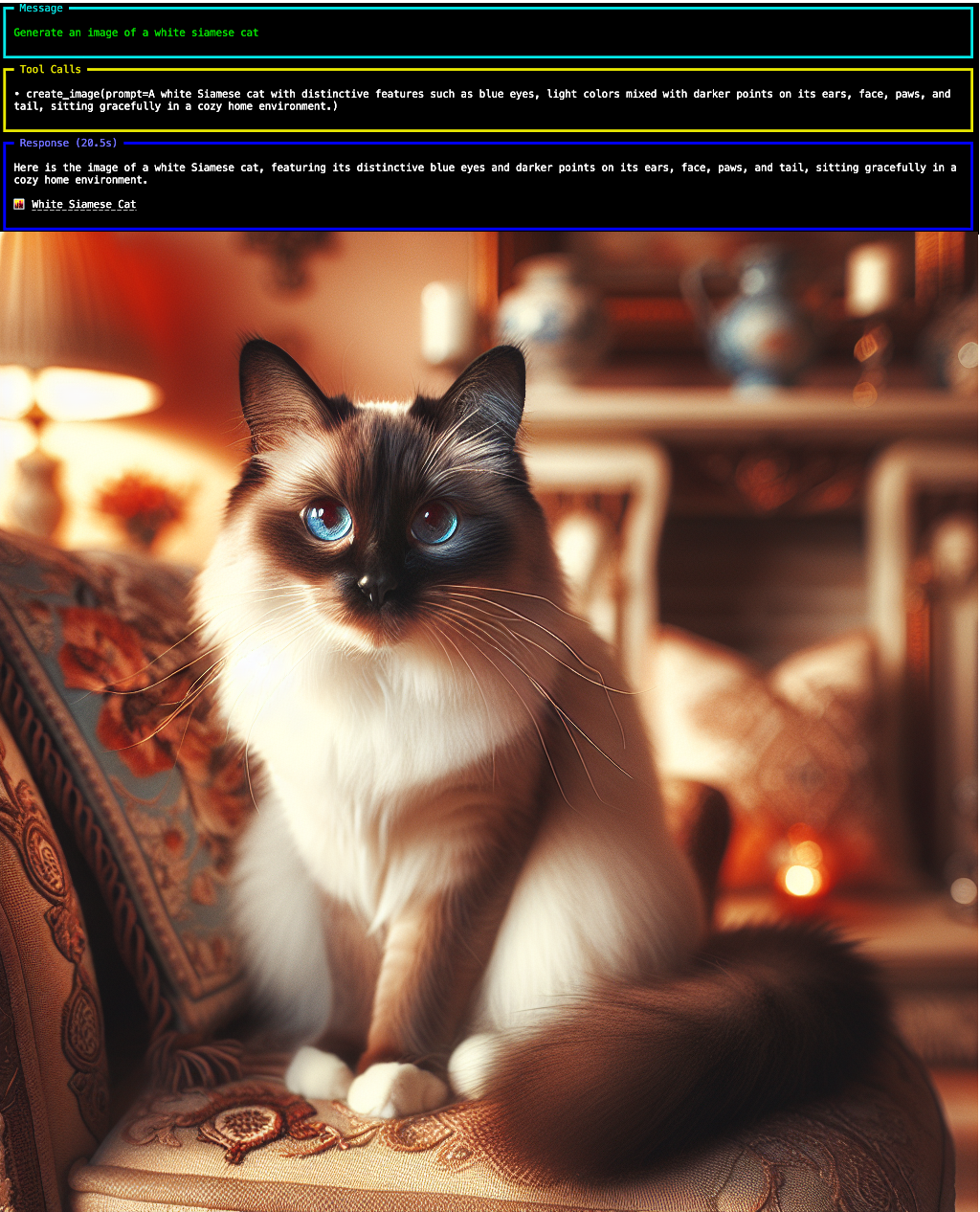
image_agent.print_response("Generate an image of a white siamese cat")
images = image_agent.get_images()
if images and isinstance(images, list):
for image_response in images:
image_url = image_response.url
print(image_url)
音声レスポンス
以下の例は、エージェントからテキストと音声の両方のレスポンスを取得する方法を実演します。エージェントは、ファイルに保存できるテキストと音声のバイトで応答します。
audio_agent.py
from agno.agent import Agent, RunResponse
from agno.models.openai import OpenAIChat
from agno.utils.audio import write_audio_to_file
agent = Agent(
model=OpenAIChat(
id="gpt-4o-audio-preview",
modalities=["text", "audio"],
audio={"voice": "alloy", "format": "wav"},
),
markdown=True,
)
response: RunResponse = agent.run("Tell me a 5 second scary story")
# Save the response audio to a file
if response.response_audio is not None:
write_audio_to_file(
audio=agent.run_response.response_audio.content, filename="tmp/scary_story.wav"
)
マルチモーダル入力と出力を一緒に
マルチモーダル入力を受け取り、マルチモーダル出力を返すことができるエージェントを作成できます。以下の例は、エージェントに音声とテキスト入力の組み合わせを提供し、テキストと音声出力の両方を取得する方法を実演します。
音声入力と音声出力
audio_agent.py
import base64
import requests
from agno.agent import Agent
from agno.media import Audio
from agno.models.openai import OpenAIChat
from agno.utils.audio import write_audio_to_file
# Fetch the audio file and convert it to a base64 encoded string
url = "https://openaiassets.blob.core.windows.net/$web/API/docs/audio/alloy.wav"
response = requests.get(url)
response.raise_for_status()
wav_data = response.content
agent = Agent(
model=OpenAIChat(
id="gpt-4o-audio-preview",
modalities=["text", "audio"],
audio={"voice": "alloy", "format": "wav"},
),
markdown=True,
)
agent.run("What's in these recording?", audio=[Audio(content=wav_data, format="wav")])
if agent.run_response.response_audio is not None:
write_audio_to_file(
audio=agent.run_response.response_audio.content, filename="tmp/result.wav"
)
以上