Lightly 1.2 : Getting Started : 自己教師あり学習の高度なコンセプト (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/17/2022 (v1.2.25)
* 本ページは、Lightly の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Getting Started : Advanced Concepts in Self-Supervised Learning
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Lightly 1.2 : Getting Started : 自己教師あり学習の高度なコンセプト
このセクションでは、lightly 周りの幾つかのより高度なトピックを見ていきます。今のところ lightly は主に対照学習 (= contrastive learning) 法にフォーカスしています。対照学習では、各サンプルの複数のビューを作成し、モデルの訓練の間、(同じサンプルに由来する) 類似のビューは互いに近くに、(異なるサンプルに由来する) 異なるビューは遠く離れるように強制します。ビューは通常は増強法を使用して取得されます。
この手続きを通して、対照学習法を使用してモデルを訓練するとき、特定の増強に対して不変性を訓練します。
異なる増強は異なる不変性をもたらします。学習したい不変性は解決したい下流タスクのタイプに大きく依存します。ここでは、増強をそれらが誘導する不変性のタイプによりグループ分けし、そしてそのような不変性が有用でありえる場合の例を示します。
例えば、自己学習モデルの訓練の間にカラー・ジッターとランダム・グレースケールを使用する場合、入力画像の 2 つの増強バージョンを特徴空間内で互いに非常に近く配置するようにモデルを訓練します。これは本質的にはカラー増強を無視してモデルを訓練することになります。
Shape 不変性
- ランダムクロップ E.g. オブジェクトが小さいか大きいかあるいは画像で部分的なだけかはケアしません。
- ランダム水平反転 E.g. 画像の左右についてはケアしません。
- ランダム垂直反転 E.g. 画像の上下についてはケアしません。これは衛星画像に対して有用です。
- ランダム回転 E.g. カメラの方向についてはケアしません。これは衛星画像に対して有用です。
テキスチャ不変性
- ガウシアンぼかし E.g. 人物の詳細はケアせず、全体の形状をします。
カラー不変性
- カラー・ジッター E.g. 自動車が青か赤色かはケアしません。
- ランダム・グレースケール E.g. 木の色はケアしません。
- ソラリゼーション E.g. 色と明るさはケアしません。
自己教師あり学習の不変性に関する幾つかの興味深い論文は :
- Demystifying Contrastive Self-Supervised Learning, S. Purushwalkam, 2020
- What Should Not Be Contrastive in Contrastive Learning, T. Xiao, 2020
Note : 妥当な増強法を選択することは対照学習を使用してモデルを訓練した結果に対して重要と思われます。例えば、猫を色で分類するモデルを作成したい場合、カラー・ジッターやランダム・グレースケールのような強いカラー増強を使用するべきではありません。
増強
Lightly は PyTorch dataloader を使用してサンプルのバッチをロードするとき、増強を適用するために collate 演算を使用します。
組み込みの collate クラス lightly.data.collate.ImageCollateFunction は SimCLR と MoCo で使用される一般的な増強のセットを提供しています。画像の単一バッチの代わりに、それはランダムに変換された画像の 2 つのバッチのタプルを返します。
コマンドライン・ツール を使用する場合、総ての SimCLR collate 増強へのアクセスを持ちます。デフォルトパラメータはここで見つかります : デフォルト設定
ガウシアンぼかし, ソラリゼーション, 及び 90 度のランダム回転は torchvision でサポートされていませんので、lightly lightly.transforms にそれらを追加しました。
lightly.data.collate.BaseCollateFunction から継承して独自の collate 関数を構築できます。
# create a dataset using SimCLR augmentations
collate_fn = lightly.data.SimCLRCollateFunction()
dataloader_train_simclr = torch.utils.data.DataLoader(
dataset_train_simclr,
collate_fn=collate_fn,
)
# same augmentation but without blur and resize images to 128x128
collate_fn = lightly.data.SimCLRCollateFunction(
input_size=128,
gaussian_blur=0.
)
dataloader_train_simclr = torch.utils.data.DataLoader(
dataset_train_simclr,
collate_fn=collate_fn,
)
Note : 確率を 0.0 に設定するか、増強が効果を持たないことを確実にすることで増強を無効にできます。例えば、ランダム・クロッピングは min_scale=1.0 を設定することで無効にできます。
増強のプレビュー
選択した画像増強が入力データセットに与える影響を理解することは非常に有用であることが多いです。lightly を使用して増強をプレビューすることを容易にする幾つかのヘルパーメソッドを提供しています。
import glob
from PIL import Image
import lightly
# let's get all jpg filenames from a folder
glob_to_data = '/datasets/clothing-dataset/images/*.jpg'
fnames = glob.glob(glob_to_data)
# load the first two images using pillow
input_images = [Image.open(fname) for fname in fnames[:2]]
# create our colalte function
collate_fn_simclr = lightly.data.SimCLRCollateFunction()
# plot the images
fig = lightly.utils.debug.plot_augmented_images(input_images, collate_fn_simclr)
# let's disable blur
collate_fn_simclr_no_blur = lightly.data.SimCLRCollateFunction()
fig = lightly.utils.debug.plot_augmented_images(input_images, collate_fn_simclr_no_blur)
# we can also use the DINO collate function instead
collate_fn_dino = lightly.data.DINOCollateFunction()
fig = lightly.utils.debug.plot_augmented_images(input_images, collate_fn_dino)
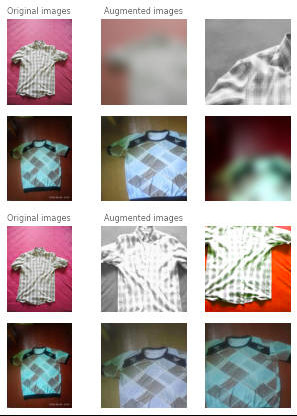
増強を素早く調べるために Jupyter ノートブックでコードを実行できます。plot_augmented_images を実行すれば、オリジナルの画像とそれらの隣に増強画像を見るはずです。

衣類データセットからの画像に対する SimCLRCollateFunction 関数のサンプル増強
画像はかなりぼやけています!けれども、私たちはモデルが小さい細部を無視することを望みません。ガウシアンぼかしを無効にして再度確認しましょう :

衣類データセットからの画像に対する SimCLRCollateFunction 関数のサンプル増強
訓練の間に DINO モデルが何を見るかを見るために DINOCollateFunction について実験を繰り返すこともできます。

衣類データセットからの画像に対する DINOCollateFunction 関数のサンプル増強
モデル
現時点で Lightly は自己教師あり学習に対して以下のモデルをサポートしています :
- SimCLR: A Simple Framework for Contrastive Learning of Visual Representations, T. Chen, 2020
- 次のチュートリアルをチェックしてください : Tutorial 3: Train SimCLR on Clothing.
- MoCo: Momentum Contrast for Unsupervised Visual Representation Learning, K. He, 2019
- 次のチュートリアルをチェックしてください : Tutorial 2: Train MoCo on CIFAR-10
- SimSiam: Exploring Simple Siamese Representation Learning, K. He, 2020
- 次のチュートリアルをチェックしてください : Tutorial 4: Train SimSiam on Satellite Images
- Barlow Twins : Self-Supervised Learning via Redundancy Reduction, S. Deny, 2021
- NNCLR : With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations, D. Dwibedi, 2021
- BYOL : Bootstrap your own latent: A new approach to self-supervised Learning, J. Grill, 2020
- SwAV : Unsupervised Learning of Visual Features by Contrasting Cluster Assignments, M. Caron, 2020
このリストに載せるべきモデルが分かりますか?GitHub の issue を追加してください 🙂
総てのモデルはバックボーンコンポーネントを持ちます。これは ResNet かもしれません。自己教師あり学習モデルを作成するときそれにバックボーンを渡します。バックボーン出力次元が、それぞれの自己教師ありモデルのヘッドコンポーネントの入力次元と確実に一致している必要があります。
Lightly は ResNet のための組み込み generator を持ちます。けれども、そのモデル・アーキテクチャは公式の ResNet 実装とは少し違っています。違いは最初の幾つかの層にあります。公式 ResNet が 7×7 畳み込みで始まるのに対して、lightly からのものは 3×3 畳み込みを持ちます。
- 3×3 畳み込みのバリエーションはより効率的で (パラメータが少なく高速な処理)、小さい入力画像 (32×32 ピクセル or 64×64 ピクセル) により良く適しています。cifar10 やマイクロコントローラでモデルを実行するためには lighty のバリエーションを使用することを勧めます (https://github.com/ARM-software/EndpointAI/tree/master/ProofOfConcepts/Vision/OpenMvMaskDefaults 参照)。
- けれども、7×7 畳み込みバリエーションは大きい画像には適しています、ストライドと追加の MaxPool2d 層により特徴数が少ないからです。ImageNet, Pascal VOC, MOCO, 等のようなデータセットで別の学術的な論文に対してベンチマークを行なうためには、torchvision 亜種を使用してください。
# create a lightly ResNet
resnet = lightly.models.ResNetGenerator('resnet-18')
# alternatively create a torchvision ResNet backbone
resnet_torchvision = torchvision.models.resnet18()
# remove the last linear layer and add an adaptive average pooling layer
backbone = nn.Sequential(
*list(resnet.children())[:-1],
nn.AdaptiveAvgPool2d(1),
)
# create a simclr model based on ResNet
class SimCLR(torch.nn.Module):
def __init__(self, backbone, hidden_dim, out_dim):
super().__init__()
self.backbone = backbone
self.projection_head = SimCLRProjectionHead(hidden_dim, hidden_dim, out_dim)
def forward(self, x):
h = self.backbone(x).flatten(start_dim=1)
z = self.projection_head(h)
return z
resnet_simclr = SimCLR(backbone, hidden_dim=512, out_dim=128)
また カスタム・バックボーン を lightly で使用することもできます。torchvision or timm モデルをどのように使用できるかを示す colab ノートブック を提供しています。
損失
対照学習のための最も一般的な損失関数と非対照手法のための symmetric negative コサイン類似度損失を提供しています。
- NTXentLoss : Normalized Temperature-scaled Cross Entropy Loss
- ドキュメントを確認してください : lightly.loss.ntx_ent_loss.NTXentLoss
- この損失は メモリバンク と組み合わせることができます。
- Negative コサイン類似度
- ドキュメントを確認してください : lightly.loss.negative_cosine_similarity.NegativeCosineSimilarity
- Barlow Twin 損失
- ドキュメントを確認してください : lightly.loss.barlow_twins_loss.BarlowTwinsLoss
- CO2 regularization 損失
- ドキュメントを確認してください : lightly.loss.regularizer.co2.CO2Regularizer
- Hypersphere 損失
- ドキュメントを確認してください : lightly.loss.hypersphere_loss.HypersphereLoss
メモリバンク
対照学習法は多くのネガティブサンプルから恩恵を受けますので、より大きなバッチサイズが望ましいです。けれども、総ての人がマルチ GPU クラスタを手元に持っているわけではありません。そのため、代替のトリックと手法が研究で導出されています。それらの一つはメモリバンクで、過去のサンプルを追加のネガティブ (サンプル) として保持します。
実際のメモリバンクの例については、Tutorial 2: Train MoCo on CIFAR-10 を見てください。
詳細はドキュメントを確認してください : lightly.loss.memory_bank.MemoryBankModuleK
# to create a NTXentLoss with a memory bank (like for MoCo) set the
# memory_bank_size parameter to a value > 0
criterion = lightly.loss.NTXentLoss(memory_bank_size=4096)
# the memory bank is used automatically for every forward pass
y0, y1 = resnet_moco(x0, x1)
loss = criterion(y0, y1)
良い埋め込みを取得する
低次元埋め込み を使用して重要なデータポイントだけを選択するワークフローを最適化します。これは 2 つの利点を持ちます :
- 低次元埋め込みはより意味のある距離尺度を持ちます。データは通常は高次元空間の多様体に在ることが分かっています (curse of dimensionality 参照)。高次元埋め込みでは非常に類似したサンプルでさえも高い L2-距離や低いコサイン類似度を持つかもしれません。
- 埋め込みに基づいてサブセットを選択する殆どのアルゴリズムは次元性でスケールします。従って低次元埋め込みは計算時間を大幅に削減できます。
ラベル付けされていないデータの良い特徴 / 表現 / 埋め込みを取得するために 自己教師あり学習 を利用します。表現の質は選択された増強に大きく依存します。例えば、健康的な葉と不健康な葉を検出する分類器を訓練したいとします。カラー増強が有効にされた自己教師ありモデルの訓練は、モデルと従って埋め込みを異なるカラーに対して不変にします。けれども、カラーは葉が健康であるか (緑) そうでないか (茶色) を決定する、葉の非常に重要な特徴であるかもしれません。
埋め込み品質のモニタリング
モデル訓練の間に埋め込み品質にアクセスする幾つかのツールを提供しています。Benchmark モジュール は総ての訓練ポックの後に検証セットで KNN ベンチマークを実行します。訓練の間の KNN 精度の測定はモデル訓練をモニタする効率的な方法でコスト高な微調整は必要としません。
表現の collapse を監視するヘルパー関数も提供しています。表現 collapse は不安定な訓練の間に起きる可能性があり、モデルが総ての画像に対して同じ、あるいは非常に類似した表現を予測するという結果になります。これはもちろんモデル訓練において破壊的です、表現には画像間で可能な限り異なって欲しいからです!std_of_l2_normalized ヘルパー関数は以下のように任意の表現上で使用できます :
from lightly.utils.debug import std_of_l2_normalized
representations = model(images)
std_of_l2_normalized(representations)
0 に近い値は表現が壊れたことを示しています。値が 1/sqrt(dimensions) に近い値、ここで dimensions は表現の次元数、は表現が安定的であることを示しています。下で、表現が崩壊した実行からのモデル訓練出力と、壊れていないものを表示します。
# run with collapse epoch: 00, loss: -0.78153, representation std: 0.02611 epoch: 01, loss: -0.96428, representation std: 0.02477 epoch: 02, loss: -0.97460, representation std: 0.01636 epoch: 03, loss: -0.97894, representation std: 0.01936 epoch: 04, loss: -0.97770, representation std: 0.01565 epoch: 05, loss: -0.98308, representation std: 0.01192 epoch: 06, loss: -0.98641, representation std: 0.01133 epoch: 07, loss: -0.98673, representation std: 0.01583 epoch: 08, loss: -0.98708, representation std: 0.01146 epoch: 09, loss: -0.98654, representation std: 0.01656 # run without collapse epoch: 00, loss: -0.35693, representation std: 0.06708 epoch: 01, loss: -0.69948, representation std: 0.05853 epoch: 02, loss: -0.74144, representation std: 0.05710 epoch: 03, loss: -0.74297, representation std: 0.05804 epoch: 04, loss: -0.71997, representation std: 0.06441 epoch: 05, loss: -0.70027, representation std: 0.06738 epoch: 06, loss: -0.70543, representation std: 0.06898 epoch: 07, loss: -0.71539, representation std: 0.06875 epoch: 08, loss: -0.72629, representation std: 0.06991 epoch: 09, loss: -0.72912, representation std: 0.06945
両者の実行で損失は減少し、モデルが進捗していることを示していることに注意してください。しかし表現の標準偏差は 2 つの実行が非常に異なっていることを示しています。最初の実行の標準偏差はゼロに向かって減少していて、これは表現が更に類似していくことを意味します。2 番目の実行の標準偏差は安定していて、この実行 (dimensions = 128) に対して 1/sqrt(dimensions) = 0.088 の期待値に近づいています。損失だけを監視していた場合、最初の実行で表現 collapse に気づかずに、そして訓練し続けて貴重な時間と計算資源を使い尽くしていたでしょう。
The example has been tested on a system running Python 3.7 and lightly 1.0.6
以上