Lightly 1.2 : Getting Started : 能動学習 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/14/2022 (v1.2.25)
* 本ページは、Lightly の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Getting Started : Active learning
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Lightly 1.2 : Getting Started : 能動学習
Lightly は数行だけの追加コードで能動学習を可能にします。アノテートされたデータセットで利用可能な情報を最大化することにより貴方のデータを最大限に活用する方法について、ここで学習してください。
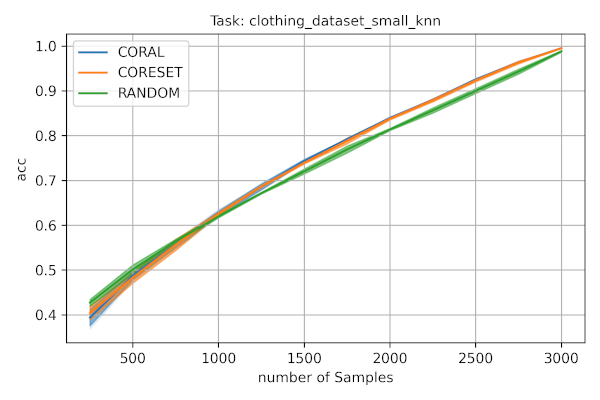
様々なサンプルを衣類データセットでどのように遂行するかを示すプロット
Lightly 能動学習を非常に簡単に利用できる一方で、最善のパフォーマンスを与えるように設計しました。更に学習するにはチュートリアルを確認してください :
- Tutorial 3: Active learning for classification
- Tutorial 4: Active Learning using Detectron2 on Comma10k
準備
読み続ける前に、Lightly Platform のセクションを確実に読んでください。特に、web-app でデータセットを作成する方法と画像と埋め込みをそれにアップロードする方法を知る必要があります。能動学習を行なうには、embeddings を持つそのようなデータセットが必要です (don’t worry, it’s free!)。
コンセプト
Lightly は能動学習のために以下のコンセプトを利用します :
ApiWorkflowClient : lightly.api.api_workflow_client.ApiWorkflowClient
ApiWorkflowClient は私たちの API に接続するために使用されます。API は埋め込みと能動学習スコアに基づいて画像の選択を処理します。ApiWorkflowClient を初期化するには、Lightly プラットフォームからの datasetId とトークンが必要です。
ActiveLearningAgent : lightly.active_learning.agents.agent.ActiveLearningAgent
ActiveLearningAgent は能動学習フレームワークのクライアント・インターフェースを構築します。それはどの画像が事前選択されて、どれからサンプリングされるかを示すことを可能にします。更に、画像の新しいバッチを取得するためにそれに問い合わせることができます。ActiveLearningAgent を初期化するには ApiWorkflowClient が必要です。
SelectionConfig : lightly.active_learning.config.selection_config.SelectionConfig
SelectionConfig は選択リクエストの設定を可能にします。具体的には、サンプル数, 選択結果の名前, そして SamplingMethod を設定できます。現在、SamplingMethod を以下のいずれかに設定できます :
- RANDOM: 一様にランダムにサンプルを選択します。
- CORESET: 多様性のあるサンプルを greedily に選択します。
- CORAL: 能動学習を行なうために CORESET とスコアを組み合わせます。
Scorer : lightly.active_learning.scorers.scorer.Scorer
Scorer はラベル付けなしの画像のセットの事前訓練済みモデルの予測を入力として取ります。それは calculate_scores メソッドを提供します、これはモデルが画像についてどの程度確信しているかに基づいて様々なスコアを評価します。選択を実行するとき、選択ストラテジー CORAL と ACTIVE_LEARNING により使用される API にスコアが渡されます。
能動学習スコアは 0.0 と 1.0 の間のスカラー値 (サンプル毎) で、そこでは 1.0 により近い値は非常に重要なサンプルであることを示します。
これらのコンポーネントがどのように相互作用するか、能動学習が Lightly でどのように行われるかを見るために読み続けてください。
初期選択
初期選択を行なう目的は (その上で) 初期モデルを訓練できるサブデータセットを得ることです。そしてモデルの出力は新しいサンプルを選択するために使用できます。そのようにして、モデルは反復的に改良できます。
初期選択を行なうには、生の、ラベル付けされていないデータとそれに応じた画像埋め込みを Lightly web-app のデータセットに追加することから始めます。これを行なう単純な方法はコマンドラインから lightly-magic を使用することです。引数 input_dir, dataset_id と token を適応させることを忘れないでください。
# use trainer.max_epochs=0 to skip training
lightly-magic input_dir='path/to/your/raw/dataset' dataset_id='xyz' token='123' trainer.max_epochs=0
それから、Python スクリプトで、ApiWorkflowClient と ActiveLearningAgent を初期化する必要があります。
import lightly
from lightly.api import ApiWorkflowClient
from lightly.active_learning.agents import ActiveLearningAgent
api_client = ApiWorkflowClient(dataset_id='xyz', token='123')
al_agent = ActiveLearningAgent(api_client)
フルデータセットからサンプリングすることは常に良いアイデアとは限りません。例えば、画像の大部分がぼやけていることはありえます。この場合、web-app でタグを作成することが可能です、これは鮮明な画像だけを含み、ActiveLearningAgent にこのタグからだけサンプリングするように知らせます。それを行なうため、エージェントのコンストラクタで query_tag_name 引数を設定します。
選択リクエストを configure してからそれを実行します :
from lightly.active_learning.config import SelectionConfig
from lightly.openapi_generated.swagger_client import SamplingMethod
# we want an initial pool of 150 images
config = SelectionConfig(n_samples=150, method=SamplingMethod.CORESET, name='initial-selection')
al_agent.query(config)
initial_selection = al_agent.labeled_set
# initial_selection now contains 150 filenames
assert len(initial_selection) == 150
問い合わせの結果は “initial-selection” という名前の web-app 内のタグです。タグは選択ストラテジーにより選択された画像を含みます。そこに向かいサンプルに渡りスクロールし、それらをアノテートする前に選択された画像をダウンロードします。代わりに、上で示されたように属性 labeled_set を通して選択された画像のファイル名にアクセスできます。
能動学習ステップ
画像の初期選択にアノテートした後、それらでモデルを訓練できます。そして訓練済みモデルはどの画像が問題を引き起こすか見つけるために使用できます。このセクションは、これらの画像がどのようにラベル付けされたデータセットに追加できるかを示します。
Lightly で能動学習を続けるため、前述の ApiWorkflowClient と ActiveLearningAgent を必要とします。新しいファイルで次の選択ステップを実行する場合、クライアントとエージェントを再度初期化しなければなりません。それらを最初期化する必要がある場合、現在の選択に pre_selected_tag_name を設定することを確実にしてください (これが最初の反復であれば、これは初期選択を行なうときに選択 config に渡した名前です)。それらを再初期化する必要がない場合には、タグの追跡が貴方のために行われることに注意してください。
# re-initializing the ApiWorkflowClient and ActiveLearningAgent
api_client = ApiWorkflowClient(dataset_id='xyz', token='123')
al_agent = ActiveLearningAgent(api_client, preselected_tag_name='initial-selection')
次のパートは能動学習を単純な選択から差別化するものです ; 訓練済みモデルはデータ上で予測を得るために使用され、これらの予測に基づいて選択ストラテジーが決定します。予測が必要とされる総てのファイル名のリストを得るには、query_set が使用できます :
# get all filenames in the query set
query_set = al_agent.query_set
ラベル付けされていない画像上で予測を得るためにこのリストを使用します。
Important : 予測は ActiveLearningAgent により返されるリストのファイル名と同じ順序にある必要があります。
次に、タスクに応じて scorer オブジェクトを作成します (下記の Scores 参照)。例えば、分類のためには、予測は numpy 配列で (行の合計が 1 になるように) 正規化される必要があります :
from lightly.active_learning.scorers import ScorerClassification
scorer = ScorerClassification(predictions)
さて今では、画像の次のバッチを得るための総てを持っています。ここで言及すべき一つの重要なことは、引数 n_samples はラベル付けされたセットの合計サイズを常に参照していることです。
# we want a total of 200 images after the first iteration (50 new samples)
# this time, we use the CORAL selection strategy and provide a scorer to the query
selection_config = SelectionConfig(n_samples=200, method=SamplingMethod.CORAL, name='al-iteration-1')
al_agent.query(selection_config, scorer)
labeled_set_iteration_1 = al_agent.labeled_set
added_set_iteration_1 = al_agent.added_set
assert len(labeled_set_iteration_1) == 200
assert len(added_set_iteration_1) == 50
前のように、web-app で見える al-iteration-1 という名前の新しいタグがあります。更に、ラベル付けされたセットの総ての画像のファイル名とこの問い合わせにより追加されたファイル名にそれぞれ属性 labeled_set と added_set を通してアクセスできます。モデルが必要な精度を獲得するまで能動学習のステップを繰り返すことができます。
web-app は埋め込みビューで能動学習スコアを見ることを可能にしますので、選択の実行なしに能動学習スコアだけを web-app にアップロードする必要があるユースケースもあります。これもまた容易に可能です :
al_agent.upload_scores(scorer)
スコアラー
Lightly は画像分類, 検出等のような一般的なコンピュータビジョン・タスクのためのスコアラーを提供しています。
能動学習スコアは 0.0 と 1.0 の間のスカラー値 (サンプル毎) です。1.0 に近い値は重要なサンプルであることを示しています。例えば、画像分類モデルに対しては高いスコアはサンプルの分類が困難であることを示しています。
画像分類
分類問題 (二値 or 他クラス) に取り組むときはこのスコアラーを使用します。
現在 3 つの不確実性スコアを提供しています、これらは http://burrsettles.com/pub/settles.activelearning.pdf , Section 3.1, page 12 に基づき、
また https://towardsdatascience.com/uncertainty-sampling-cheatsheet-ec57bc067c0b で説明されています。それら総てについて、総てのクラスが同じ確率を持つ場合にはスコアは最高値となり、モデルが単一クラスに 100% の確率を割り当てる場合にはスコアは 0.0 になります。それらは考慮するクラス確信度の数で異なります。
uncertainty_least_confidence
このスコアは 1.0 から最高の確信度予測を引いたものです。最も確率の高いクラスについての確信度が低いときにそれは高く (1.0 に近づく) なります。
uncertainty_margin
このスコアは 1.0 から最高値と 2 番目に高い確信度予測の間の差を引いたものです。それはモデルが 2 つの最も確率の高いクラスの間で決定できないときに高く (1.0 に近づく) なります。
uncertainty_entropy
このスコアラーは予測のエントロピーを計算します。総てのクラスの確信度がサンプルのエントロピーを計算するために使用されます。それはモデルが総てのクラス間で決定できないとき高く (1.0 に近づく) なります。
分類スコアラーの使用方法についての詳細はここを見てください : lightly.active_learning.scorers.classification.ScorerClassification
オブジェクト検出
境界ボックスを使用してオブジェクト検出問題に取り組むときこのスコアラーを使用します。オブジェクト検出スコアラーは入力が ObjectDetectionOutput 形式にあることを必要とします。
モデル予測が以下を含むことを想定しています :
- shape (x0, y0, x1, y1) の境界ボックス
- 各境界ボックスに対する objectness_probability
- 各境界ボックスに対する classification_probabilities
フォーマットについてはここで詳細を見つけられます : lightly.active_learning.utils.object_detection_output.ObjectDetectionOutput
また、境界ボックス毎の確率と関連ラベルだけから構成されるモデル出力形式を扱うためのヘルパーメソッドも提供しています。
lightly.active_learning.utils.object_detection_output.ObjectDetectionOutput.from_scores
現在、以下のスコアラーが利用可能です :
- object_frequency このスコアは画像のオブジェクトの数を測定します。多くのオブジェクトを含む風景を望む場合このスコアラーを使用します。これは自動運転における知覚のようなコンピュータビジョン・タスクに対して適しています。高い値を持つ (1.0 に近づく) サンプルはデータセット内で最も多くのオブジェクトを含みます。
- objectness_least_confidence このスコアは 1.0 から最高の確信度予測値の平均を引いたものです。このスコアは、モデルがオブジェクトとオブジェクトのクラスを見つけたかの両者について不確かである場合に画像を選択するために使用します。高い値を持つ (1.0 に近づく) サンプルはモデルが良い境界ボックスを予測する確信度を低いものです。
- classification_scores これらのスコアは画像毎の各オブジェクト検出に対して、この検出に対するクラス確率予測から計算されます。そして最大値を取ることで画像毎に一つのスコアに reduce されます。特に以下をサポートします :
- uncertainty_least_confidence
- uncertainty_margin
- uncertainty_entropy
スコアは分類のためのスコアラーを使用して計算されます。
オブジェクト検出スコアラーの使い方についての詳細はここを見てください :
lightly.active_learning.scorers.detection.ScorerObjectDetection
画像セグメンテーション
モデルをセマンティック・セグメンテーションのために訓練しているときこのスコアラーを使用します。セマンティック・セグメンテーション・スコアラーは pixelwise なラベル予測のリストか generator を想定します。
モデル予測が shape W x H x C であることを想定しています、ここで :
- W は画像の幅
- H は画像の高さ
- C はセグメンテーションクラスの数 (e.g. 2 for 背景 vs 前景)
現在、以下のスコアラーが利用可能です :
- classification_scores これらのスコアはセグメンテーションをピクセル単位の分類タスクとして扱います。分類の不確実性スコアはピクセル単位で計算されて平均を取ることで画像毎に単一スコアに reduce されます。特に、以下をサポートします :
- uncertainty_least_confidence
- uncertainty_margin
- uncertainty_entropy
スコアは分類のためのスコアラーを使用して計算されます。
セマンティックセグメンテーション・スコアラーを使用する方法についての詳細は、ここを見てください :
lightly.active_learning.scorers.semantic_segmentation.ScorerSemanticSegmentation
以上