PyTorch 1.8 ノート : 分散データ並列 (処理) (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/08/2021 (1.8.1)
* 本ページは、PyTorch 1.8 Notes の以下のページを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |

ノート : 分散データ並列 (処理)
警告 : torch.nn.parallel.DistributedDataParallel の実装は時間とともに進化しています。この設計ノートは v1.4 の時点での状態を基に書かれています。
torch.nn.parallel.DistributedDataParallel (DDP) は分散データ並列訓練を透過的に遂行します。このページはそれがどのように動作するかを記述して実装の詳細を明らかにします。
サンプル
単純な torch.nn.parallel.DistributedDataParallel サンプルから始めましょう。このサンプルはローカルモデルとして torch.nn.Linear を使用し、それを DDP でラップし、そして DDP モデル上で 1 回 forward パス、1 回 backward パス、そして optimizer ステップを実行します。その後、ローカルモデルのパラメータは更新され、そして異なるプロセス上の総てのモデルは正確に同じであるはずです。
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
内部デザイン
このセクションは一つの反復内の総てのステップの詳細を掘り下げることにより torch.nn.parallel.DistributedDataParallel の内部でそれがどのように動作するかを明らかにします。
- 前提条件: DDP は通信のために c10d ProcessGroup に依存します。そのため、アプリケーションは DDP を構築する前に ProcessGroup インスタンスを作成しなければなりません。
- コンストラクション: DDP コンストラクタはローカルモジュールへの参照を取り、そして総てのモジュールレプリカが正確に同じ状態から開始することを確実にするために rank 0 のプロセスから state_dict() をグループの総ての他のプロセスにブロードキャストします。そして、各 DDP プロセスはローカル Recucer を作成します、これは後で backward パスの間に勾配同期を処理します。通信効率を改良するため、Reducer はパラメータ勾配をバケットに体系化して、一度に一つのバケットを reduce します。バケットサイズは DDP コンストラクタの bucket_cap_mb 引数を設定することにより configure できます。パラメータ勾配からバケットへのマッピングはコンストラクション時にバケットサイズ制限とパラメータサイズに基づいて決定されます。モデルパラメータは指定モデルからの Model.parameters() の (おおよそ) 反対の順序でバケットに割当てられます。反対の順序を使用する理由は DDP は、backward パスの間にだいたいその順序で勾配の準備ができていることを想定するからです。下の図は例を示します。grad0 と grad1 は bucket1にあり、そして他の 2 つの勾配は bucket0 にあることに注意してください。もちろん、この仮定は常に正しいとは限りません、そしてその時、それは DDP backward スピードを害する可能性があります、何故ならば Reducer はできるだけ早い時間に通信を始められないからです。バケット化に加えて、Reducer はまた構築時に autograd フックを登録します、パラメータ毎に 1 つのフックです。これらのフックは勾配が準備できたとき backward パスの間にトリガーが引かれます。
- Foward パス : DDP は入力を取りそれをローカルモデルに渡し、そして find_unused_parameters が True に設定されている場合ローカルモデルからの出力を解析します。このモードはモデルのサブグラフ上で backward を実行することを可能にし、DDP はモデル出力から autograd グラフを辿りそして総ての未使用のパラメータをリダクションのために準備完了とマークすることにより backward パスでどのパラメータが関係するか見つけます。backward パスの間、Reducer はまだ準備ができていないパラメータを待つだけですが、それは依然として総てのバケットを reduce します。パラメータ勾配を準備完了とマークすることは当面は DDP がバケットをスキップする役には立ちませんが、backward パスの間 DDP が存在しない勾配を永久に待つことを回避します。autograd グラフを辿ることは追加のオーバーヘッドが発生するため、アプリケーションは必要に応じて find_unused_parameters を True に設定するべきであることに注意してください。
- Backward パス : backward() 関数は損失 Tensor 上で直接呼び出され、これは DDP の制御外で、そして DDP は勾配同期のトリガーのために構築時に登録された autograd フックを使用します。一つの勾配が準備完了したとき、その grad アキュムレータ上の対応する DDP フックが発火し、そして DDP はそのパラメータ勾配をリダクションのために準備ができたとしてマークします。一つのバケットの勾配が総て準備ができたとき、Reducer は総てのプロセスに渡る勾配の平均を計算するためにそのバケット上で非同期 allreduce を起動します。総てのバケットが準備出来たとき、Reducer は総ての allreduce 演算が終わるまで待つためにブロックします。これが成されたとき、平均された勾配は総てのパラメータの param.grad フィールドに書かれます。そして backward パスの後、異なる DDP プロセスに渡る同じ対応するパラメータ上の grad フィールドは同じであるべきです。
- Optimizer ステップ : optimizer の観点からは、それはローカルモデルを最適化しています。総ての DDP プロセス上のモデルレプリカは同期を維持することができます、何故ならばそれらは総て同じ状態から開始して総ての反復で同じ平均勾配を持つからです。
Note : DDP は総てのプロセス上の Reducer インスタンスに正確に同じ順序で allreduce を呼び出すことを要求します、これは実際のバケットが準備できた順序の代わりに常にバケット・インデックスで allreduce を実行することにより成されます。プロセスに渡るミスマッチな allreduce 順序は誤った結果か DDP backward ハングに繋がる可能性があります。
実装
以下は DDP 実装コンポーネントへの参照 (= pointers) です。スタックされた図はコードの構造を示します。
ProcessGroup
- ProcessGroup.hpp : 総てのプロセスグループ実装の抽象 API を含みます。c10d ライブラリはそのまま利用できる 3 つの実装を提供します、つまり ProcessGroupGloo, ProcessGroupNCCL と ProcessGroupMPI です。DistributedDataParallel は初期化の間に rank0 のプロセスからモデル状態を他に送るために ProcessGroup::broadcast() を、そして勾配を合計するために ProcessGroup::allreduce() を使用します。
- Store.hpp : プロセスグループ・インスタンスが互いを見つけるためにランデブー・サービスを支援します。
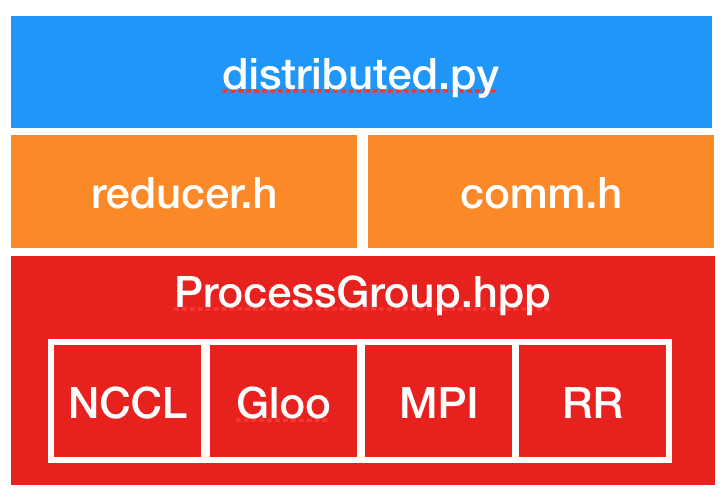
DistributedDataParallel
- distributed.py : DDP のための Python エントリポイントです。それは nn.parallel.DistributedDataParallel モジュールのための初期化ステップと forward 関数を実装しています、これは C++ ライブラリ内を呼び出します。その _sync param 関数は一つの DDP プロセスが複数のデバイス上で動作するとき intra-process パラメータを同期し、そしてまた rank 0 のプロセスから他の総てのプロセスにモデル・バッファをブロードキャストします。inter-プロセス・パラメータ同期は Reducer.cpp で発生します。
- comm.h : coalesced ブロードキャスト・ヘルパー関数を実装します、これは初期化の間にモデル状態をブロードキャストして forward パスの前にモデルバッファを同期するために呼び出されます。
- reducer.h : backward パスでの勾配同期のための中心的な実装を提供します。それは 3 つのエントリポイント関数を持ちます :
- Reducer : distributed.py でコンストラクタが呼び出されます、これは勾配アキュムレータに Reducer::autograd_hook() を登録します。
- autograd_hook() 関数は勾配の準備ができたときに autograd エンジンにより呼びだされます。
- prepare_for_backward() は distributed.py で DDP forward パスの最後に呼び出されます。それは DDP コンストラクタで find_unused_parameters が True に設定されているとき使用されていないパラメータを見つけるために autograd グラフを辿ります。
以上