Detectron2 0.3: 初心者 Colab チュートリアル (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 03/02/2021 (0.3)
* 本ページは、Detectron2 ドキュメントの以下のページを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- Windows PC のブラウザからご参加が可能です。スマートデバイスもご利用可能です。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ |
| Facebook: https://www.facebook.com/ClassCatJP/ |

Detectron2 : 初心者 Colab チュートリアル
Welcome to detectron2! これは detectron2 の公式 colab チュートリアルです。ここでは、以下を含む、detectron2 の幾つかの基本的な使用方法を通り抜けます :
- 既存の detectron2 モデルで、画像や動画上で推論を実行します。
- 新しいデータセットで detectron2 モデルを訓練します。
“File -> Open in playground mode” によりこのチュートリアルのコピーを作成してそこで変更を行なうことができます。このチュートリアルへのアクセスを リクエストしないでください。
Detectron2 をインストールする
# install dependencies:
!pip install pyyaml==5.1
import torch, torchvision
print(torch.__version__, torch.cuda.is_available())
!gcc --version
# opencv is pre-installed on colab
!pip install imgaug==0.2.6
(※ 訳注: imgaug のバージョンを合わせておくとエラーが回避できます。)
# install detectron2: (Colab has CUDA 10.1 + torch 1.7)
# See https://detectron2.readthedocs.io/tutorials/install.html for instructions
import torch
assert torch.__version__.startswith("1.7")
#!pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
!pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu101/torch1.7/index.html
#exit(0) # After installation, you need to "restart runtime" in Colab. This line can also restart runtime
# Some basic setup:
# Setup detectron2 logger
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# import some common libraries
import numpy as np
import os, json, cv2, random
from google.colab.patches import cv2_imshow
# import some common detectron2 utilities
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
事前訓練 detectron2 モデルを実行する
最初に COCO データセットから画像をダウンロードします :
!wget http://images.cocodataset.org/val2017/000000439715.jpg -q -O input.jpg
im = cv2.imread("./input.jpg")
cv2_imshow(im)

それから、この画像上で推論を実行するために detectron2 config と detectron2 DefaultPredictor を作成します。
cfg = get_cfg()
# add project-specific config (e.g., TensorMask) here if you're not running a model in detectron2's core library
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set threshold for this model
# Find a model from detectron2's model zoo. You can use the https://dl.fbaipublicfiles... url as well
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
# look at the outputs. See https://detectron2.readthedocs.io/tutorials/models.html#model-output-format for specification
print(outputs["instances"].pred_classes)
print(outputs["instances"].pred_boxes)
tensor([17, 0, 0, 0, 0, 0, 0, 0, 25, 0, 25, 25, 0, 0, 24],
device='cuda:0')
Boxes(tensor([[126.6035, 244.8977, 459.8291, 480.0000],
[251.1083, 157.8127, 338.9731, 413.6379],
[114.8496, 268.6864, 148.2352, 398.8111],
[ 0.8217, 281.0327, 78.6072, 478.4210],
[ 49.3954, 274.1229, 80.1545, 342.9808],
[561.2248, 271.5816, 596.2755, 385.2552],
[385.9072, 270.3125, 413.7130, 304.0397],
[515.9295, 278.3744, 562.2792, 389.3802],
[335.2409, 251.9167, 414.7491, 275.9375],
[350.9300, 269.2060, 386.0984, 297.9081],
[331.6292, 230.9996, 393.2759, 257.2009],
[510.7349, 263.2656, 570.9865, 295.9194],
[409.0841, 271.8646, 460.5582, 356.8722],
[506.8767, 283.3257, 529.9403, 324.0392],
[594.5663, 283.4820, 609.0577, 311.4124]], device='cuda:0'))
# We can use `Visualizer` to draw the predictions on the image.
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])

カスタムデータセット上で訓練する
このセクションでは、既存の detecron2 モデルを新しい形式のカスタムデータセット上でどのように訓練するかを示します。
バルーン (風船) セグメンテーション・データセット を利用します、これは一つのクラス: balloon を持つだけです。detectron2 のモデル zoo で利用可能な COCO データセット上で事前訓練された既存のモデルからバルーン・セグメンテーション・モデルを訓練します。
COCO データセットは “balloon” カテゴリーを持たないことに注意してください。数分でこの新しいクラスを認識することができます。
データセットを準備する
# download, decompress the data
!wget https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
!unzip balloon_dataset.zip > /dev/null
detectron2 カスタム・データセット・チュートリアル に従って、バルーン・データセットを detectron2 に登録します。ここでは、データセットはカスタム形式にありますので、それをパースする関数を書いてそれを detectron2 の標準形式に準備します。ユーザはカスタム形式にあるデータセットを使用するときそのような関数を書くべきです。より詳細についてはチュートリアルを見てください。
# if your dataset is in COCO format, this cell can be replaced by the following three lines:
# from detectron2.data.datasets import register_coco_instances
# register_coco_instances("my_dataset_train", {}, "json_annotation_train.json", "path/to/image/dir")
# register_coco_instances("my_dataset_val", {}, "json_annotation_val.json", "path/to/image/dir")
from detectron2.structures import BoxMode
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
データローディングが正しいことを検証するため、訓練セットのランダムに選択したサンプルのアノテーションを可視化しましょう :
dataset_dicts = get_balloon_dicts("balloon/train")
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=balloon_metadata, scale=0.5)
out = visualizer.draw_dataset_dict(d)
cv2_imshow(out.get_image()[:, :, ::-1])


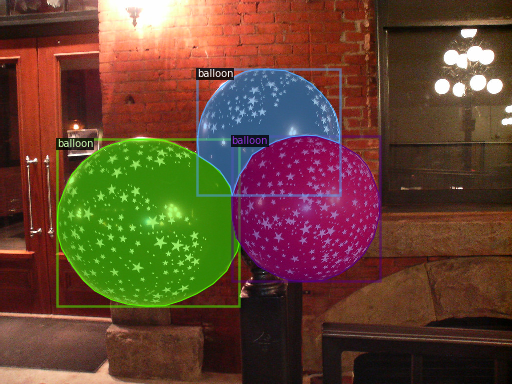
訓練!
今は、COCO-事前訓練 R50-FPN Mask R-CNN モデルをバルーン・データセット上で再調整しましょう。それは Colab の K80 GPU 上で 300 反復を訓練するために ~6 分かかります、あるいは P100 GPU 上で ~2 分です。
from detectron2.engine import DefaultTrainer
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.DATASETS.TRAIN = ("balloon_train",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") # Let training initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 300 # 300 iterations seems good enough for this toy dataset; you will need to train longer for a practical dataset
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon). (see https://detectron2.readthedocs.io/tutorials/datasets.html#update-the-config-for-new-datasets)
# NOTE: this config means the number of classes, but a few popular unofficial tutorials incorrect uses num_classes+1 here.
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
CPU times: user 2 µs, sys: 1 µs, total: 3 µs
Wall time: 5.25 µs
[03/01 17:24:35 d2.engine.defaults]: Model:
GeneralizedRCNN(
(backbone): FPN(
(fpn_lateral2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_block): LastLevelMaxPool()
(bottom_up): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)
)
(proposal_generator): RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(objectness_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
(roi_heads): StandardROIHeads(
(box_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(box_head): FastRCNNConvFCHead(
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc1): Linear(in_features=12544, out_features=1024, bias=True)
(fc_relu1): ReLU()
(fc2): Linear(in_features=1024, out_features=1024, bias=True)
(fc_relu2): ReLU()
)
(box_predictor): FastRCNNOutputLayers(
(cls_score): Linear(in_features=1024, out_features=2, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=4, bias=True)
)
(mask_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(14, 14), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(14, 14), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(mask_head): MaskRCNNConvUpsampleHead(
(mask_fcn1): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn3): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn4): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(deconv): ConvTranspose2d(256, 256, kernel_size=(2, 2), stride=(2, 2))
(deconv_relu): ReLU()
(predictor): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
)
[03/01 17:24:37 d2.data.build]: Removed 0 images with no usable annotations. 61 images left.
[03/01 17:24:37 d2.data.build]: Distribution of instances among all 1 categories:
| category | #instances |
|:----------:|:-------------|
| balloon | 255 |
| | |
[03/01 17:24:37 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in training: [ResizeShortestEdge(short_edge_length=(640, 672, 704, 736, 768, 800), max_size=1333, sample_style='choice'), RandomFlip()]
[03/01 17:24:37 d2.data.build]: Using training sampler TrainingSampler
[03/01 17:24:37 d2.data.common]: Serializing 61 elements to byte tensors and concatenating them all ...
[03/01 17:24:37 d2.data.common]: Serialized dataset takes 0.17 MiB
Skip loading parameter 'roi_heads.box_predictor.cls_score.weight' to the model due to incompatible shapes: (81, 1024) in the checkpoint but (2, 1024) in the model! You might want to double check if this is expected.
Skip loading parameter 'roi_heads.box_predictor.cls_score.bias' to the model due to incompatible shapes: (81,) in the checkpoint but (2,) in the model! You might want to double check if this is expected.
Skip loading parameter 'roi_heads.box_predictor.bbox_pred.weight' to the model due to incompatible shapes: (320, 1024) in the checkpoint but (4, 1024) in the model! You might want to double check if this is expected.
Skip loading parameter 'roi_heads.box_predictor.bbox_pred.bias' to the model due to incompatible shapes: (320,) in the checkpoint but (4,) in the model! You might want to double check if this is expected.
Skip loading parameter 'roi_heads.mask_head.predictor.weight' to the model due to incompatible shapes: (80, 256, 1, 1) in the checkpoint but (1, 256, 1, 1) in the model! You might want to double check if this is expected.
Skip loading parameter 'roi_heads.mask_head.predictor.bias' to the model due to incompatible shapes: (80,) in the checkpoint but (1,) in the model! You might want to double check if this is expected.
[03/01 17:24:42 d2.engine.train_loop]: Starting training from iteration 0
[03/01 17:24:51 d2.utils.events]: eta: 0:02:07 iter: 19 total_loss: 2.037 loss_cls: 0.6386 loss_box_reg: 0.5968 loss_mask: 0.6854 loss_rpn_cls: 0.03356 loss_rpn_loc: 0.007503 time: 0.4446 data_time: 0.0253 lr: 4.9953e-06 max_mem: 2722M
[03/01 17:25:00 d2.utils.events]: eta: 0:01:57 iter: 39 total_loss: 1.946 loss_cls: 0.605 loss_box_reg: 0.572 loss_mask: 0.6595 loss_rpn_cls: 0.02964 loss_rpn_loc: 0.008898 time: 0.4469 data_time: 0.0081 lr: 9.9902e-06 max_mem: 2723M
[03/01 17:25:09 d2.utils.events]: eta: 0:01:49 iter: 59 total_loss: 1.909 loss_cls: 0.5733 loss_box_reg: 0.69 loss_mask: 0.6033 loss_rpn_cls: 0.02132 loss_rpn_loc: 0.007664 time: 0.4521 data_time: 0.0118 lr: 1.4985e-05 max_mem: 2723M
[03/01 17:25:19 d2.utils.events]: eta: 0:01:41 iter: 79 total_loss: 1.761 loss_cls: 0.494 loss_box_reg: 0.6504 loss_mask: 0.5506 loss_rpn_cls: 0.0376 loss_rpn_loc: 0.01298 time: 0.4569 data_time: 0.0064 lr: 1.998e-05 max_mem: 2846M
[03/01 17:25:29 d2.utils.events]: eta: 0:01:33 iter: 99 total_loss: 1.679 loss_cls: 0.453 loss_box_reg: 0.713 loss_mask: 0.4617 loss_rpn_cls: 0.02309 loss_rpn_loc: 0.006994 time: 0.4629 data_time: 0.0076 lr: 2.4975e-05 max_mem: 2881M
[03/01 17:25:39 d2.utils.events]: eta: 0:01:24 iter: 119 total_loss: 1.522 loss_cls: 0.4074 loss_box_reg: 0.6142 loss_mask: 0.4338 loss_rpn_cls: 0.02925 loss_rpn_loc: 0.003638 time: 0.4685 data_time: 0.0121 lr: 2.997e-05 max_mem: 2881M
[03/01 17:25:48 d2.utils.events]: eta: 0:01:15 iter: 139 total_loss: 1.373 loss_cls: 0.3526 loss_box_reg: 0.6416 loss_mask: 0.3331 loss_rpn_cls: 0.01023 loss_rpn_loc: 0.005562 time: 0.4695 data_time: 0.0076 lr: 3.4965e-05 max_mem: 2881M
[03/01 17:25:58 d2.utils.events]: eta: 0:01:05 iter: 159 total_loss: 1.368 loss_cls: 0.3384 loss_box_reg: 0.6182 loss_mask: 0.3355 loss_rpn_cls: 0.02713 loss_rpn_loc: 0.007957 time: 0.4711 data_time: 0.0066 lr: 3.996e-05 max_mem: 2881M
[03/01 17:26:07 d2.utils.events]: eta: 0:00:56 iter: 179 total_loss: 1.227 loss_cls: 0.2912 loss_box_reg: 0.609 loss_mask: 0.2663 loss_rpn_cls: 0.01641 loss_rpn_loc: 0.006059 time: 0.4703 data_time: 0.0085 lr: 4.4955e-05 max_mem: 2881M
[03/01 17:26:17 d2.utils.events]: eta: 0:00:47 iter: 199 total_loss: 1.275 loss_cls: 0.2932 loss_box_reg: 0.6743 loss_mask: 0.2624 loss_rpn_cls: 0.02639 loss_rpn_loc: 0.01679 time: 0.4710 data_time: 0.0059 lr: 4.995e-05 max_mem: 2881M
[03/01 17:26:26 d2.utils.events]: eta: 0:00:37 iter: 219 total_loss: 1.033 loss_cls: 0.2311 loss_box_reg: 0.6131 loss_mask: 0.1849 loss_rpn_cls: 0.01269 loss_rpn_loc: 0.004724 time: 0.4717 data_time: 0.0088 lr: 5.4945e-05 max_mem: 2881M
[03/01 17:26:35 d2.utils.events]: eta: 0:00:28 iter: 239 total_loss: 1.021 loss_cls: 0.1958 loss_box_reg: 0.5855 loss_mask: 0.1688 loss_rpn_cls: 0.01187 loss_rpn_loc: 0.006714 time: 0.4707 data_time: 0.0068 lr: 5.994e-05 max_mem: 2881M
[03/01 17:26:45 d2.utils.events]: eta: 0:00:18 iter: 259 total_loss: 0.9762 loss_cls: 0.1784 loss_box_reg: 0.5562 loss_mask: 0.199 loss_rpn_cls: 0.0209 loss_rpn_loc: 0.00828 time: 0.4719 data_time: 0.0098 lr: 6.4935e-05 max_mem: 2881M
[03/01 17:26:55 d2.utils.events]: eta: 0:00:09 iter: 279 total_loss: 0.897 loss_cls: 0.1472 loss_box_reg: 0.5509 loss_mask: 0.1271 loss_rpn_cls: 0.0147 loss_rpn_loc: 0.00634 time: 0.4720 data_time: 0.0069 lr: 6.993e-05 max_mem: 2881M
[03/01 17:27:06 d2.utils.events]: eta: 0:00:00 iter: 299 total_loss: 0.8252 loss_cls: 0.1369 loss_box_reg: 0.5189 loss_mask: 0.1358 loss_rpn_cls: 0.01604 loss_rpn_loc: 0.006912 time: 0.4731 data_time: 0.0059 lr: 7.4925e-05 max_mem: 2881M
[03/01 17:27:06 d2.engine.hooks]: Overall training speed: 298 iterations in 0:02:20 (0.4732 s / it)
[03/01 17:27:06 d2.engine.hooks]: Total training time: 0:02:23 (0:00:02 on hooks)
# Look at training curves in tensorboard:
%load_ext tensorboard
%tensorboard --logdir output
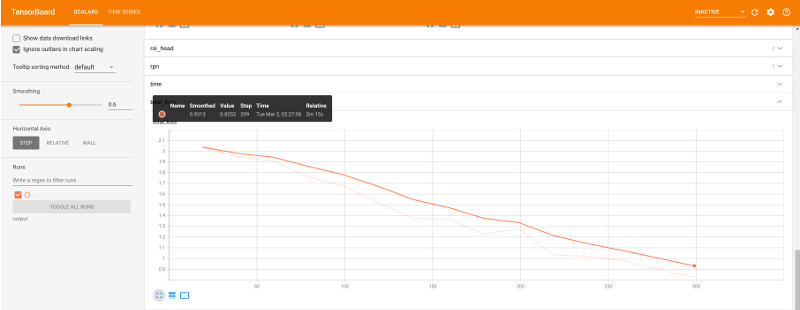
訓練モデルを使用して推論 & 評価
今は、バルーン検証データセット上で訓練モデルで推論を実行しましょう。最初に、訓練したてのモデルを使用して predictor (予測器) を作成しましょう :
# Inference should use the config with parameters that are used in training
# cfg now already contains everything we've set previously. We changed it a little bit for inference:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth") # path to the model we just trained
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set a custom testing threshold
predictor = DefaultPredictor(cfg)
それから、予測結果を可視化するために幾つかのサンプルをランダムに選択します。
from detectron2.utils.visualizer import ColorMode
dataset_dicts = get_balloon_dicts("balloon/val")
for d in random.sample(dataset_dicts, 3):
im = cv2.imread(d["file_name"])
outputs = predictor(im) # format is documented at https://detectron2.readthedocs.io/tutorials/models.html#model-output-format
v = Visualizer(im[:, :, ::-1],
metadata=balloon_metadata,
scale=0.5,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])



COCO API で実装された AP メトリックを使用してそのパフォーマンスを評価することもできます。これは ~70 の AP を与えます。Not bad!
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
evaluator = COCOEvaluator("balloon_val", ("bbox", "segm"), False, output_dir="./output/")
val_loader = build_detection_test_loader(cfg, "balloon_val")
print(inference_on_dataset(trainer.model, val_loader, evaluator))
# another equivalent way to evaluate the model is to use `trainer.test`
[03/01 17:33:37 d2.evaluation.coco_evaluation]: 'balloon_val' is not registered by `register_coco_instances`. Therefore trying to convert it to COCO format ...
[03/01 17:33:37 d2.data.datasets.coco]: Converting annotations of dataset 'balloon_val' to COCO format ...)
[03/01 17:33:37 d2.data.datasets.coco]: Converting dataset dicts into COCO format
[03/01 17:33:37 d2.data.datasets.coco]: Conversion finished, #images: 13, #annotations: 50
[03/01 17:33:37 d2.data.datasets.coco]: Caching COCO format annotations at './output/balloon_val_coco_format.json' ...
[03/01 17:33:38 d2.data.build]: Distribution of instances among all 1 categories:
| category | #instances |
|:----------:|:-------------|
| balloon | 50 |
| | |
[03/01 17:33:38 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in inference: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='choice')]
[03/01 17:33:38 d2.data.common]: Serializing 13 elements to byte tensors and concatenating them all ...
[03/01 17:33:38 d2.data.common]: Serialized dataset takes 0.04 MiB
[03/01 17:33:38 d2.evaluation.evaluator]: Start inference on 13 images
[03/01 17:33:46 d2.evaluation.evaluator]: Inference done 11/13. 0.1456 s / img. ETA=0:00:00
[03/01 17:33:47 d2.evaluation.evaluator]: Total inference time: 0:00:02.439180 (0.304898 s / img per device, on 1 devices)
[03/01 17:33:47 d2.evaluation.evaluator]: Total inference pure compute time: 0:00:01 (0.141308 s / img per device, on 1 devices)
[03/01 17:33:47 d2.evaluation.coco_evaluation]: Preparing results for COCO format ...
[03/01 17:33:47 d2.evaluation.coco_evaluation]: Saving results to ./output/coco_instances_results.json
[03/01 17:33:47 d2.evaluation.coco_evaluation]: Evaluating predictions with unofficial COCO API...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
COCOeval_opt.evaluate() finished in 0.01 seconds.
Accumulating evaluation results...
COCOeval_opt.accumulate() finished in 0.00 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.665
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.844
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.821
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.186
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.469
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.817
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.226
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.710
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.770
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.567
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.629
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.870
[03/01 17:33:47 d2.evaluation.coco_evaluation]: Evaluation results for bbox:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:------:|:------:|:------:|
| 66.484 | 84.420 | 82.127 | 18.607 | 46.869 | 81.654 |
Loading and preparing results...
DONE (t=0.01s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *segm*
COCOeval_opt.evaluate() finished in 0.02 seconds.
Accumulating evaluation results...
COCOeval_opt.accumulate() finished in 0.00 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.762
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.832
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.829
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.080
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.531
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.942
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.250
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.786
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.846
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.600
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.682
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.963
[03/01 17:33:47 d2.evaluation.coco_evaluation]: Evaluation results for segm:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:-----:|:------:|:------:|
| 76.200 | 83.177 | 82.855 | 8.017 | 53.119 | 94.166 |
OrderedDict([('bbox', {'AP': 66.48390600789553, 'AP50': 84.41990405567722, 'AP75': 82.12726107549864, 'APs': 18.606789250353607, 'APm': 46.86938018143075, 'APl': 81.654286935886}), ('segm', {'AP': 76.19973157950476, 'AP50': 83.17713464245247, 'AP75': 82.85469691837302, 'APs': 8.017326732673267, 'APm': 53.11887378013511, 'APl': 94.16620875922416})])
他のタイプの組込みモデル
# Inference with a keypoint detection model
cfg = get_cfg() # get a fresh new config
cfg.merge_from_file(model_zoo.get_config_file("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set threshold for this model
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])
# Inference with a panoptic segmentation model
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml"))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml")
predictor = DefaultPredictor(cfg)
panoptic_seg, segments_info = predictor(im)["panoptic_seg"]
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_panoptic_seg_predictions(panoptic_seg.to("cpu"), segments_info)
cv2_imshow(out.get_image()[:, :, ::-1])

動画上でパノラマ的 (= panoptic) セグメンテーションを実行する
# This is the video we're going to process
from IPython.display import YouTubeVideo, display
video = YouTubeVideo("ll8TgCZ0plk", width=500)
display(video)
# Install dependencies, download the video, and crop 5 seconds for processing
!pip install youtube-dl
!pip uninstall -y opencv-python-headless opencv-contrib-python
!apt install python3-opencv # the one pre-installed have some issues
!youtube-dl https://www.youtube.com/watch?v=ll8TgCZ0plk -f 22 -o video.mp4
!ffmpeg -i video.mp4 -t 00:00:06 -c:v copy video-clip.mp4
# Run frame-by-frame inference demo on this video (takes 3-4 minutes) with the "demo.py" tool we provided in the repo.
!git clone https://github.com/facebookresearch/detectron2
!python detectron2/demo/demo.py --config-file detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml --video-input video-clip.mp4 --confidence-threshold 0.6 --output video-output.mkv \
--opts MODEL.WEIGHTS detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl
# Download the results
from google.colab import files
files.download('video-output.mkv')
補足 : 動作環境確認
(訳注: 動作環境への依存度が高いので確認しておきます。)
!nvidia-smi
Mon Mar 1 17:18:14 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.39 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 48C P8 10W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
!nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2019 NVIDIA Corporation Built on Sun_Jul_28_19:07:16_PDT_2019 Cuda compilation tools, release 10.1, V10.1.243
!ls /usr/local -l
total 68 drwxr-xr-x 1 root root 4096 Feb 25 14:52 bin lrwxrwxrwx 1 root root 9 Feb 24 17:43 cuda -> cuda-10.1 drwxr-xr-x 16 root root 4096 Feb 24 17:40 cuda-10.0 drwxr-xr-x 1 root root 4096 Feb 24 17:42 cuda-10.1 drwxr-xr-x 1 root root 4096 Feb 25 14:19 etc drwxr-xr-x 2 root root 4096 Jan 18 21:02 games drwxr-xr-x 2 root root 4096 Feb 25 14:32 _gcs_config_ops.so drwxr-xr-x 1 root root 4096 Feb 25 14:41 include drwxr-xr-x 1 root root 4096 Feb 25 14:41 lib -rw-r--r-- 1 root root 1636 Feb 25 14:35 LICENSE.txt drwxr-xr-x 3 root root 4096 Feb 25 14:32 licensing lrwxrwxrwx 1 root root 9 Jan 18 21:02 man -> share/man drwxr-xr-x 2 root root 4096 Jan 18 21:03 sbin -rw-r--r-- 1 root root 7291 Feb 25 14:35 setup.cfg drwxr-xr-x 1 root root 4096 Feb 25 14:19 share drwxr-xr-x 2 root root 4096 Jan 18 21:02 src drwxr-xr-x 2 root root 4096 Feb 25 14:42 xgboost
!ls /usr/local/cuda-10.1/lib64/libcuda*
/usr/local/cuda-10.1/lib64/libcudadevrt.a /usr/local/cuda-10.1/lib64/libcudart.so /usr/local/cuda-10.1/lib64/libcudart.so.10.1 /usr/local/cuda-10.1/lib64/libcudart.so.10.1.243 /usr/local/cuda-10.1/lib64/libcudart_static.a
!ls -l /usr/lib/x86_64-linux-gnu/libcudnn.so*
lrwxrwxrwx 1 root root 29 Feb 12 18:20 /usr/lib/x86_64-linux-gnu/libcudnn.so -> /etc/alternatives/libcudnn_so lrwxrwxrwx 1 root root 17 Oct 27 2019 /usr/lib/x86_64-linux-gnu/libcudnn.so.7 -> libcudnn.so.7.6.5 -rw-r--r-- 1 root root 428711256 Oct 27 2019 /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
! ls /usr/lib64-nvidia/libcuda*
/usr/lib64-nvidia/libcuda.so /usr/lib64-nvidia/libcuda.so.460.32.03 /usr/lib64-nvidia/libcuda.so.1
以上