AI SDK は LLM からテキストを生成したりそれをストリーミングする 2 つの関数: generateText, streamText を提供します。ツール呼び出しや構造化データ生成のような高度な LLM の機能はテキスト生成の上に構築されます。
Vercel AI SDK 6 : AI SDK Core – テキストの生成とストリーミング
作成 : Masashi Okumura (@classcat.com)
作成日時 : 01/21/2026
バージョン : ai@6.0.42
* 本記事は ai-sdk.dev/docs の以下のページを参考にし、独自翻訳した上でまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
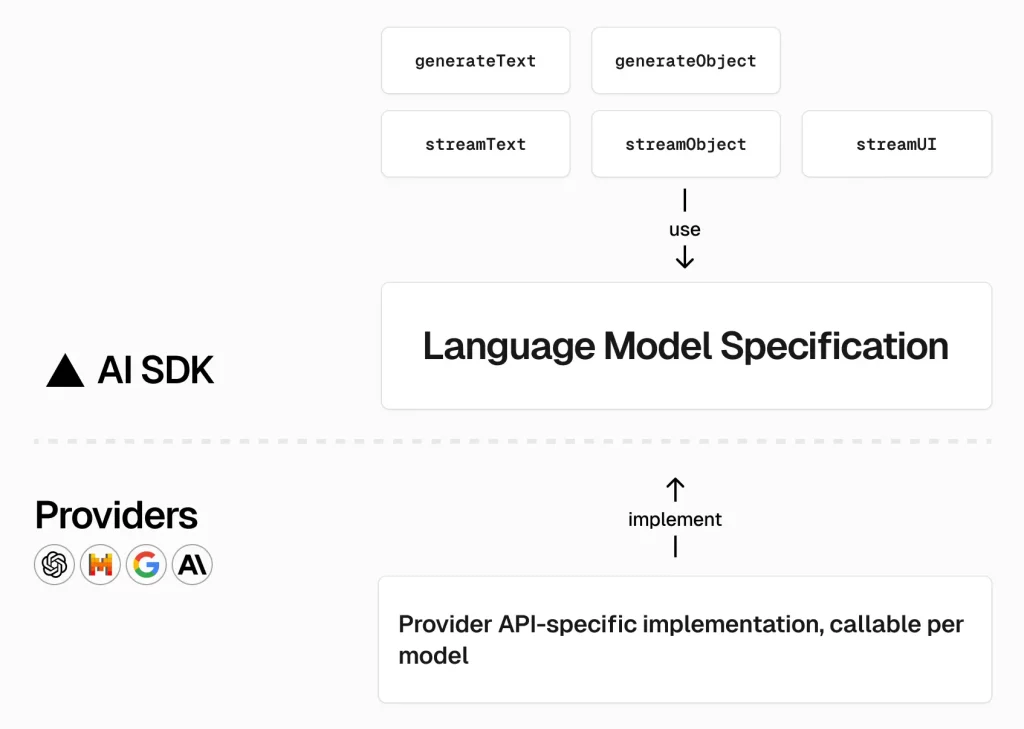
Vercel AI SDK 6.x : AI SDK Core – テキストの生成とストリーミング
大規模言語モデル (LLM) は、指示や処理すべき情報を含めることが可能な、プロンプトに対してテキストをレスポンスで生成できます。例えば、レシピを考える、メールの下書きを作成する、ドキュメントを要約することをモデルに求めることができます。
AI SDK は LLM からテキストを生成したりそれをストリーミングする 2 つの関数を提供します :
- generateText : 指定されたプロンプトとモデルに対してテキストを生成します。
- streamText : 与えられたプロンプトとモデルに対してテキストをストリーミングします。
ツール呼び出しや構造化データ生成のような高度な LLM の機能はテキスト生成の上に構築されます。
generateText
generateText 関数を使用してテキストを生成できます。この関数は、テキストを作成する必要がある非対話的ユースケース (e.g. メールの下書きや Web ページの要約) や、ツールを使用するエージェントに最適です。
Gateway
import { generateText } from 'ai';
const { text } = await generateText({
model: "openai/gpt-4o-mini",
prompt: 'Write a vegetarian lasagna recipe for 4 people.',
});
より高度なプロンプトを使用して、より複雑な指示とコンテンツを使用してテキストを生成できます :
Gateway
import { generateText } from 'ai';
const { text } = await generateText({
model: "openai/gpt-4o-mini",
system:
'You are a professional writer. ' +
'You write simple, clear, and concise content.',
prompt: `Summarize the following article in 3-5 sentences: ${article}`,
});
generateText の result オブジェクトは、すべての必要なデータが利用可能になった際に確定されるいくつかの Promise を含みます :
- result.content: 最後のステップで生成されたコンテンツ。
- result.text: 生成テキスト。
- result.reasoning: 最後のステップでモデルが生成した完全な推論。
- result.reasoningText: モデルの推論テキスト (一部のモデルでのみ利用可能)。
- result.files: 最後のステップで生成されたファイル。
- result.sources: 最後のステップで参照として使用されたソース (一部のモデルでのみ利用可能)。
- result.toolCalls: 最後のステップで実行されたツール呼び出し。
- result.toolResults: 最後のステップからのツール呼び出しの結果。
- result.finishReason: モデルがテキスト生成を終了した理由。
- result.rawFinishReason: 生成が終了した本来の (raw) 理由 (プロバイダーから)。
- result.usage: テキスト生成の最後のステップの間のモデルの使用量。
- result.totalUsage: ステップ全体にわたる総計使用量 (複数ステップの生成の場合)。
- result.warnings: モデルプロバイダーからの警告 (e.g. サポートされていない設定)。
- result.request: 追加のリクエスト情報。
- result.response: レスポンスメッセージとボディを含む、追加のレスポンス情報。
- result.providerMetadata: 追加のプロバイダー固有のメタデータ。
- result.steps: ステップ全体の詳細、中間ステップに関する情報取得のために有用です。
- result.output: 出力仕様を使用して生成された構造化出力。
レスポンスヘッダ & ボディへのアクセス
モデルプロバイダーからの完全なレスポンスにアクセスする必要がある場合があります、例えばプロバイダー固有のヘッダやボディコンテンツへのアクセスです。
response プロバティを使用して本来のレスポンスヘッダやボディにアクセスすることができます :
import { generateText } from 'ai';
const result = await generateText({
// ...
});
console.log(JSON.stringify(result.response.headers, null, 2));
console.log(JSON.stringify(result.response.body, null, 2));
onFinish コールバック
generateText を使用する場合、最後のステップが終了した後にトリガーされる onFinish コールバックを提供できます (API リファレンス)。それはテキスト、使用状況の情報、終了理由、メッセージ、ステップ、合計使用量、等を含みます :
Gateway
import { generateText } from 'ai';
const result = await generateText({
model: "openai/gpt-4o-mini",
prompt: 'Invent a new holiday and describe its traditions.',
onFinish({ text, finishReason, usage, response, steps, totalUsage }) {
// your own logic, e.g. for saving the chat history or recording usage
const messages = response.messages; // messages that were generated
},
});
streamText
モデルとプロンプトに依存して、大規模言語モデル (LLM) はそのレスポンスの生成の完了までに 1 分かかる場合があります。この遅延は、ユーザが即時の応答を期待する、チャットボットやリアルタイムアプリケーションのような対話的ユースケースについては受け入れがたい場合があります。
SDK Core は、LLM からのテキスト・ストリーミングを簡素化する streamText 関数を提供します :
Gateway
import { streamText } from 'ai';
const result = streamText({
model: "openai/gpt-4o-mini",
prompt: 'Invent a new holiday and describe its traditions.',
});
// example: use textStream as an async iterable
for await (const textPart of result.textStream) {
console.log(textPart);
}
ℹ️ result.textStream is both a ReadableStream and an AsyncIterable.
⚠️ streamText immediately starts streaming and suppresses errors to prevent server crashes. Use the onError callback to log errors.
streamText を単独で使用することも、AI SDK UI や AI SDK RSC との組み合わせで使用することもできます。result オブジェクトは AI SDK UI への統合を容易にするいくつかのヘルパー関数を含みます :
- result.toUIMessageStreamResponse(): Next.js App Router API ルートで使用できる、UI メッセージ・ストリームの (ツール呼び出し等を含む) HTTP レスポンスを作成します。
- result.pipeUIMessageStreamToResponse(): UI メッセージ・ストリームの差分出力を Node.js レスポンスのようなオブジェクトに書き込みます。
- result.toTextStreamResponse(): 単純なテキストストリームの HTTP レスポンスを作成します。
- result.pipeTextStreamToResponse(): テキストの差分出力を Node.js レスポンスのようなオブジェクトに書き込みます。
それはまた、ストリームが終了した際に確定されるいくつかの Promise も提供します :
- result.content: 最後のステップで生成されたコンテンツ。
- result.text: 生成テキスト。
- result.reasoning: モデルが生成した完全な推論。
- result.reasoningText: モデルの推論テキスト (一部のモデルでのみ利用可能)。
- result.files: 最後のステップでモデルにより生成されたファイル。
- result.sources: 最後のステップで参照として使用されたソース (一部のモデルでのみ利用可能)。
- result.toolCalls: 最後のステップで実行されたツール呼び出し。
- result.toolResults: 最後のステップで生成されたツールの結果。
- result.finishReason: モデルがテキスト生成を終了した理由。
- result.rawFinishReason: 生成が終了した本来の (raw) 理由 (プロバイダーから)。
- result.usage: テキスト生成の最後のステップの間のモデルの使用量。
- result.totalUsage: ステップ全体にわたる総計使用量 (複数ステップの生成の場合)。
- result.warnings: モデルプロバイダーからの警告 (e.g. サポートされていない設定)。
- result.steps: すべてのステップの詳細、中間ステップに関する情報を取得するのに役立ちます。
- result.request: 最後のステップからの追加のリクエスト情報。
- result.response: 最後のステップからの追加のレスポンス情報。
- result.providerMetadata: 最後のステップからの追加のプロバイダー固有のメタデータ。
onError コールバック
streamText はすぐにストリーミングを開始し、モデルを待つことなくデータの送信を可能にします。エラーはストリームの一部となり、例えばサーバのクラッシュを防ぐためにスローされません。
エラーをログ記録するには、エラーが発生したときにトリガーされる onError コールバックを提供できます。
Gateway
import { streamText } from 'ai';
const result = streamText({
model: "openai/gpt-4o-mini",
prompt: 'Invent a new holiday and describe its traditions.',
onError({ error }) {
console.error(error); // your error logging logic here
},
});
onChunk コールバック
streamText を使用する場合、ストリームの各チャンク毎にトリガーされる onChunk コールバックを提供できます。
それは以下のチャンク型を受け取ります :
- text
- reasoning
- source
- tool-call
- tool-input-start
- tool-input-delta
- tool-result
- raw
Gateway
import { streamText } from 'ai';
const result = streamText({
model: "openai/gpt-4o-mini",
prompt: 'Invent a new holiday and describe its traditions.',
onChunk({ chunk }) {
// implement your own logic here, e.g.:
if (chunk.type === 'text') {
console.log(chunk.text);
}
},
});
onFinish コールバック
streamText を使用する場合、ストリーミングが終了する際にトリガーされる onFinish コールバックを提供できます (API リファレンス)。それはテキスト、使用状況の情報、終了理由、メッセージ、ステップ、合計使用量、等を含みます :
Gateway
import { streamText } from 'ai';
const result = streamText({
model: "openai/gpt-4o-mini",
prompt: 'Invent a new holiday and describe its traditions.',
onFinish({ text, finishReason, usage, response, steps, totalUsage }) {
// your own logic, e.g. for saving the chat history or recording usage
const messages = response.messages; // messages that were generated
},
});
fullStream プロパティ
fullStream プロパティを使用してすべてのイベントを含むストリームを読み取ることができます。これは、独自 UI を実装したり、ストリームを別の方法で処理したい場合に役立ちます。fullStream プロパティを使用する方法の例が以下です :
Gateway
import { streamText } from 'ai';
import { z } from 'zod';
const result = streamText({
model: "openai/gpt-4o-mini",
tools: {
cityAttractions: {
inputSchema: z.object({ city: z.string() }),
execute: async ({ city }) => ({
attractions: ['attraction1', 'attraction2', 'attraction3'],
}),
},
},
prompt: 'What are some San Francisco tourist attractions?',
});
for await (const part of result.fullStream) {
switch (part.type) {
case 'start': {
// handle start of stream
break;
}
case 'start-step': {
// handle start of step
break;
}
case 'text-start': {
// handle text start
break;
}
case 'text-delta': {
// handle text delta here
break;
}
case 'text-end': {
// handle text end
break;
}
case 'reasoning-start': {
// handle reasoning start
break;
}
case 'reasoning-delta': {
// handle reasoning delta here
break;
}
case 'reasoning-end': {
// handle reasoning end
break;
}
case 'source': {
// handle source here
break;
}
case 'file': {
// handle file here
break;
}
case 'tool-call': {
switch (part.toolName) {
case 'cityAttractions': {
// handle tool call here
break;
}
}
break;
}
case 'tool-input-start': {
// handle tool input start
break;
}
case 'tool-input-delta': {
// handle tool input delta
break;
}
case 'tool-input-end': {
// handle tool input end
break;
}
case 'tool-result': {
switch (part.toolName) {
case 'cityAttractions': {
// handle tool result here
break;
}
}
break;
}
case 'tool-error': {
// handle tool error
break;
}
case 'finish-step': {
// handle finish step
break;
}
case 'finish': {
// handle finish here
break;
}
case 'error': {
// handle error here
break;
}
case 'raw': {
// handle raw value
break;
}
}
}
ストリーム変換
experimental_transform オプションを使用してストリームを変換できます。これは、例えば、テキストストリームのフィルタリング、変更、スムージングのために有用です。
この変換は、コールバックが呼び出され、Promise が確定される前に適用されます。例えば、すべてのテキストを大文字変更する変換がある場合、onFinish コールバックは変換されたテキストを受け取ります。
例
以下の例では、様々なフレームワークで generateText と streamText を実際に確認できます :
generateText
- Node.js でテキスト生成を学習
- Next.js で Route ハンドラを使用したテキスト生成を学習 (AI SDK UI)
- Next.js でサーバ・アクションを使用したテキスト生成を学習 (AI SDK RSC)
streamText
- Node.js でテキストのストリーミングを学習
- Next.js で Route ハンドラを使用したテキストのストリーミングを学習 (AI SDK UI)
- Next.js でサーバ・アクションを使用したテキストのストリーミングを学習 (AI SDK RSC)
以上