知識は、エージェントが実行時に検索することでより良い意思決定を行い (動的少数ショット学習) 正確な応答 (エージェント型 RAG) を提供できる、ドメイン固有情報です。知識はベクトルデータベースに保存され、このオンデマンド検索パターンはエージェント型 RAG と呼ばれます。
Agno : ユーザガイド : コンセプト : エージェント – 知識
作成 : クラスキャット・セールスインフォメーション
作成日時 : 07/22/2025
バージョン : Agno 1.7.4
* 本記事は docs.agno.com の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
Agno ユーザガイド : コンセプト : エージェント – 知識
知識は、エージェントが実行時に検索することでより良い意思決定を行い (動的少数ショット学習) 正確な応答 (エージェント型 RAG) を提供できる、ドメイン固有情報です。知識はベクトルデータベースに保存され、このオンデマンド検索パターンはエージェント型 RAG と呼ばれます。
動的少数ショット学習: Text2Sql エージェント
例: Text2Sql エージェントを構築する場合、テーブルスキーマ、カラム名、デーt型、サンプルクエリー、よくある「落とし穴」を提供して最適な SQL クエリーの生成を支援する必要があります。もちろんこれらすべてをシステムプロンプトに置いていくのではなく、代わりにこの情報をベクトルデータベースに保存し、エージェントが実行時にクエリーできるようにします。この情報を使用して、エージェントは最適な SQL クエリーを生成できます。これは動的少数ショット学習と呼ばれます。
Agno エージェントはデフォルトでエージェント型 RAG を使用します、つまり知識をエージェントに提供する場合、それは実行時に、タスクを達成するために必要な特定の情報をこの知識ベースを検索します。
エージェントに知識を追加するための擬似的なステップは :
from agno.agent import Agent, AgentKnowledge
# Create a knowledge base for the Agent
knowledge_base = AgentKnowledge(vector_db=...)
# Add information to the knowledge base
knowledge_base.load_text("The sky is blue")
# Add the knowledge base to the Agent and
# give it a tool to search the knowledge base as needed
agent = Agent(knowledge=knowledge_base, search_knowledge=True)
以下の方法でエージェントに知識ベースへのアクセスを与えることができます :
- search_knowledge=True を設定して search_knowledge_base() ツールをエージェントに追加できます。エージェントに knowledge を追加する場合、デフォルトで search_knowledge は True になります。
- add_references=True を設置すると、知識ベースからの参照をエージェントのプロンプトに自動的に追加できます。これは従来の 2023 年の RAG アプローチです
ベクトル・データベース
任意のタイプのストレージが知識ベースとして動作できますが、ベクトルデータベースが、密度が高い情報から関連する結果を素早く検索取得するためのベストソリューションを提供します。ベクトルデータベースがエージェントとともにどのように使用されるかが以下です :
- 情報をチャンクに分割する。
知識を小さいチャンクに分割して、検索クエリーが関連結果だけを返すことを確実にします。
- 知識ベースをロードする。
チャンクを埋め込みベクトルに変換して、それらをベクトルデータベースに保存します。
- 知識ベースを検索する。
ユーザがメッセージを送信すると、入力メッセージを埋め込みに変換して、ベクトルデータベースで最近傍を「検索」します。
例: PDF 知識ベースを備えた RAG エージェント
PDF から質問に答える RAG エージェントを構築しましょう。
Step 1: PgVector の実行
PgVector はエージェント用のストレージを提供することもできるので、ベクトル db として使用しましょう。docker desktop をインストールして、以下を使用して PgVector をポート 5532 で実行します :
docker run -d \
-e POSTGRES_DB=ai \
-e POSTGRES_USER=ai \
-e POSTGRES_PASSWORD=ai \
-e PGDATA=/var/lib/postgresql/data/pgdata \
-v pgvolume:/var/lib/postgresql/data \
-p 5532:5432 \
--name pgvector \
agnohq/pgvector:16
Step 2: 従来の RAG
検索拡張生成 (RAG, Retrieval Augmented Generation) は、モデルの応答を改良するために「プロンプトに関連情報を詰め込む」ことを意味します。これは 2 ステップのプロセスです :
- 知識ベースから関連情報を取得する。
- プロンプトを拡張してモデルにコンテキストを提供します。
レシピの PDF から質問に答える従来の RAG エージェントを構築しましょう。
- ライブラリのインストール
pip を使用して必要なライブラリをインストールします。
pip install -U pgvector pypdf "psycopg[binary]" sqlalchemy - 従来の RAG エージェントの作成
以下の内容でファイル traditional_rag.py を作成します。
traditional_rag.py
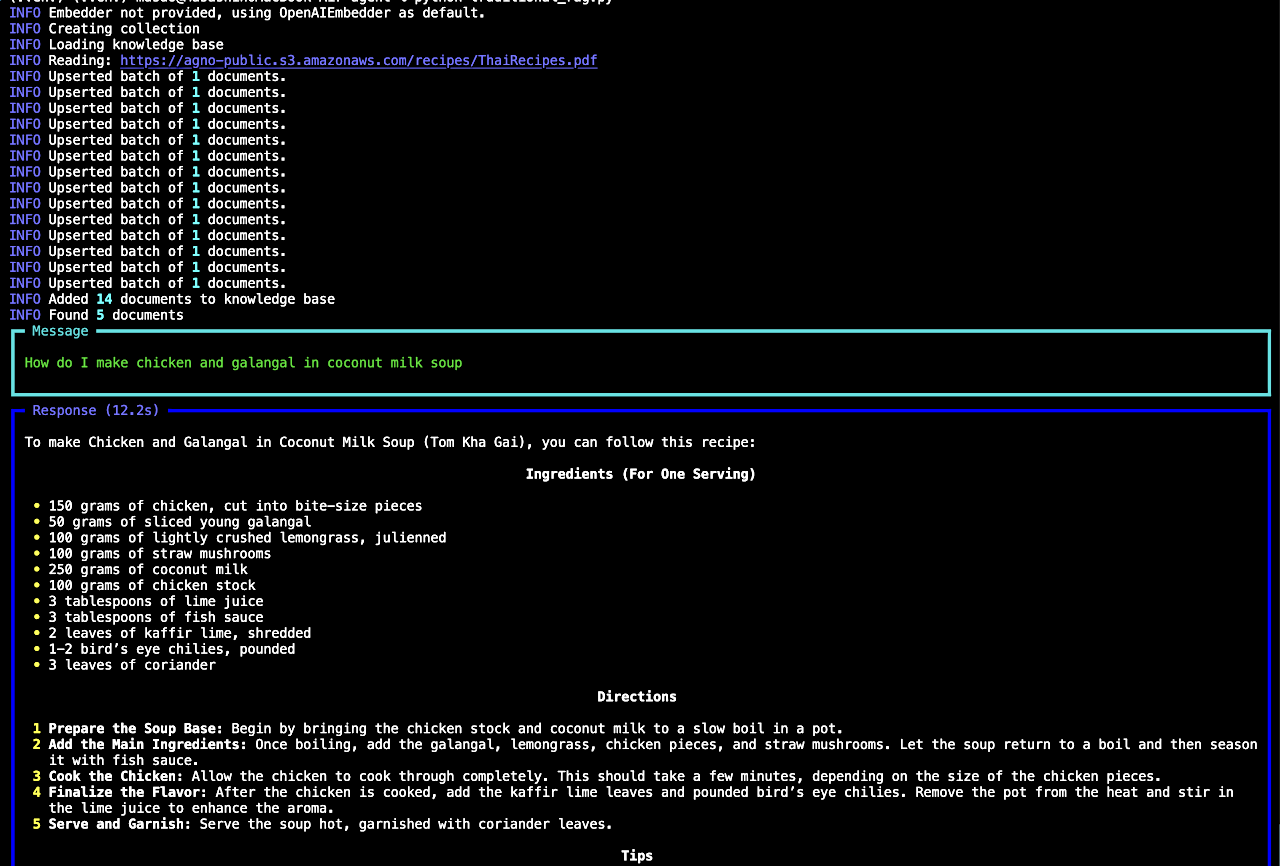
from agno.agent import Agent from agno.models.openai import OpenAIChat from agno.knowledge.pdf_url import PDFUrlKnowledgeBase from agno.vectordb.pgvector import PgVector, SearchType db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai" knowledge_base = PDFUrlKnowledgeBase( # Read PDF from this URL urls=["https://agno-public.s3.amazonaws.com/recipes/ThaiRecipes.pdf"], # Store embeddings in the `ai.recipes` table vector_db=PgVector(table_name="recipes", db_url=db_url, search_type=SearchType.hybrid), ) # Load the knowledge base: Comment after first run knowledge_base.load(upsert=True) agent = Agent( model=OpenAIChat(id="gpt-4o"), knowledge=knowledge_base, # Enable RAG by adding references from AgentKnowledge to the user prompt. add_references=True, # Set as False because Agents default to `search_knowledge=True` search_knowledge=False, markdown=True, # debug_mode=True, ) agent.print_response("How do I make chicken and galangal in coconut milk soup") - エージェントの実行
エージェントを実行します (知識ベースのロードに数秒かかります)。
python traditional_rag.py
Step 3: エージェント型 RAG
上記の従来の RAG では、add_references=True は常に知識ベースからの情報を、質問に関係があるか有用であるかにかかわらず、プロンプトに追加します。
エージェント型 RAG では、知識ベースにアクセスする必要があるか、そして知識ベースを照会するのにどのような検索パラメータが必要であるかをエージェントが決定します。
search_knowledge=True and read_chat_history=True を設定すると、エージェントに必要に応じて知識とチャット履歴を検索するツールを提供します。
- エージェント型 RAG エージェントの作成
以下の内容でファイル agentic_rag.py を作成します。
agentic_rag.py
from agno.agent import Agent from agno.models.openai import OpenAIChat from agno.knowledge.pdf_url import PDFUrlKnowledgeBase from agno.vectordb.pgvector import PgVector, SearchType db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai" knowledge_base = PDFUrlKnowledgeBase( urls=["https://agno-public.s3.amazonaws.com/recipes/ThaiRecipes.pdf"], vector_db=PgVector(table_name="recipes", db_url=db_url, search_type=SearchType.hybrid), ) # Load the knowledge base: Comment out after first run knowledge_base.load(upsert=True) agent = Agent( model=OpenAIChat(id="gpt-4o"), knowledge=knowledge_base, # Add a tool to search the knowledge base which enables agentic RAG. search_knowledge=True, # Add a tool to read chat history. read_chat_history=True, show_tool_calls=True, markdown=True, # debug_mode=True, ) agent.print_response("How do I make chicken and galangal in coconut milk soup", stream=True) agent.print_response("What was my last question?", markdown=True) - エージェントの実行
エージェントの実行
python agentic_rag.py
以上