LangServe 0.2 : 概要 : サンプル・アプリケーション解説
作成 : クラスキャット セールスインフォメーション
作成日時 : 07/10/2024
* 本ページは、github : langchain-ai/langserve の以下のページを参考にまとめ直したものです :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 本件に関するお問合せは下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
LangServe 0.2 : 概要 : サンプル・アプリケーション解説
サーバ
OpenAI チャットモデル、Anthropic チャットモデル、そして Anthropic モデルを使用してトピックに関するジョークを言うチェインを配備するサーバの例を示します :
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
add_routes(
app,
ChatOpenAI(model="gpt-3.5-turbo-0125"),
path="/openai",
)
add_routes(
app,
ChatAnthropic(model="claude-3-haiku-20240307"),
path="/anthropic",
)
model = ChatAnthropic(model="claude-3-haiku-20240307")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes(
app,
prompt | model,
path="/joke",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
このスニペットについて以下で解説します。
1. インポート
必要なライブラリをインポートします :
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
- FastAPI は API サーバを構築するために使用します。
- langchain.prompts と langchain.chat_models はそれぞれ、LangChain のプロンプトテンプレートとチャットモデルを使用するクラスを含みます。
- langserve の add_routes は、LangChain アプリケーションのルーティング設定を行うメソッドです。
2. FastAPI の初期化
タイトル、バージョン、説明を引数にして FastAPI インスタンスを作成します :
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
3. OpenAI チャットモデルをルートに追加
ChatOpenAI は標準的な Runnable インターフェイス を実装しています。
これを以下のように add_routes によりルートとして追加することで、ChatOpenAI を使用するエンドポイントを追加できます。/openai にリクエストが送られたときこのチャットモデルが処理を行うようになります。
add_routes(
app,
ChatOpenAI(model="gpt-3.5-turbo-0125"),
path="/openai",
)
4. ChatAnthropic チャットモデルをルートに追加
以下のようにして ChatAnthropic を使用するエンドポイントを追加できます。/anthropic にリクエストが送られたときこのチャットモデルが処理を行うようになります。
add_routes(
app,
ChatAnthropic(model="claude-3-haiku-20240307"),
path="/anthropic",
)
5. プロンプトと ChatAnthropic の組み合わせを使ったルートを追加
更に、プロンプトテンプレートと ChatAnthropic モデルを組み合わせた処理を行うルートを追加します。このルートは /joke にリクエストが送られると、指定されたトピックに関するジョークを生成します。
model = ChatAnthropic(model="claude-3-haiku-20240307")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes(
app,
prompt | model,
path="/joke",
)
6. サーバの起動
uvicornを使って FastAPI サーバをローカルホストのポート8000で起動します。
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
補足 1. Gemini の利用
Gemini を利用する場合は、langchain-google-genai をインストールした上で :
pip install -U langchain-google-genai
以下のコードを使用します :
from langchain_google_genai import ChatGoogleGenerativeAI
add_routes(
app,
ChatGoogleGenerativeAI(model="gemini-1.5-pro"),
path="/google",
)
model = ChatGoogleGenerativeAI(model="gemini-1.5-pro")
prompt = ChatPromptTemplate.from_template("{topic} について冗談を言ってね")
add_routes(
app,
prompt | model,
path="/joke",
)
補足 2. CORS
ブラウザからエンドポイントを呼び出す場合、CORS ヘッダも設定する必要があります。そのためには FastAPI の組み込みミドルウェアを利用できます :
from fastapi.middleware.cors import CORSMiddleware
# Set all CORS enabled origins
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
)
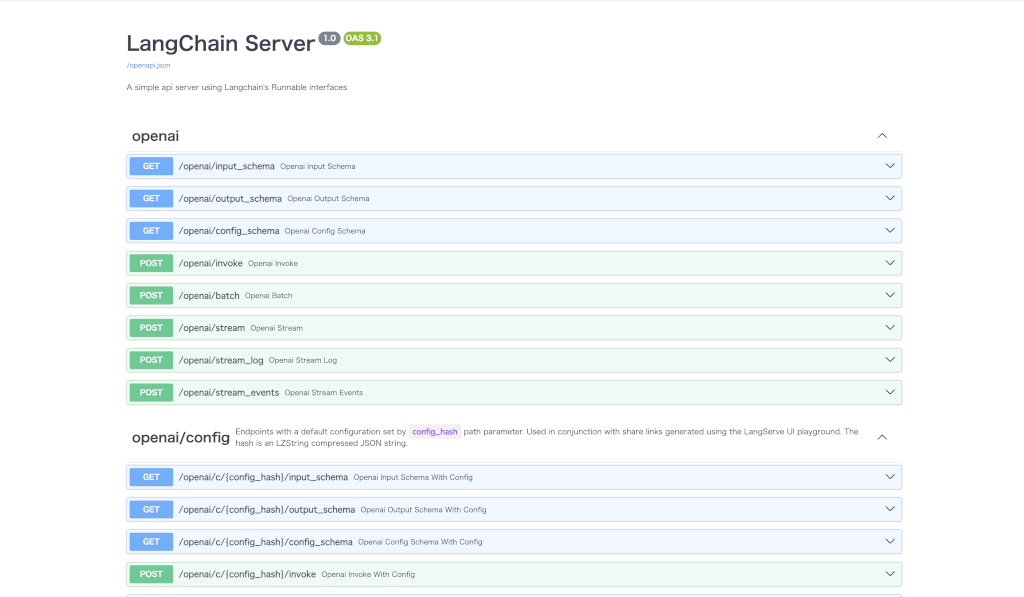
Docs
上記のサーバを配備した場合、以下を使用して生成された OpenAPI docs を見ることができます :
⚠️ pydantic v2 を使用している場合、invoke, batch, stream, stream_log については docs は生成されません。詳細は以下の Pydantic セクションを参照してください。
curl localhost:8000/docs
make sure to add the /docs suffix.
⚠️ インデックスページは by design で定義されていませんので、”curl localhost:8000″ または URL へのアクセスは 404 を返します。/ でコンテンツを望む場合、エンドポイント @app.get(“/”) を定義します。
クライアント
上記のサーバコードをベースにした、幾つかのクライアントコードを示します :
Python SDK
import asyncio
from langchain.schema import SystemMessage, HumanMessage
from langserve import RemoteRunnable
openai = RemoteRunnable("http://localhost:8000/openai/")
gemini = RemoteRunnable("http://localhost:8000/google/")
joke_chain = RemoteRunnable("http://localhost:8000/joke/")
prompt = [
SystemMessage(content='ネコのように振る舞って話してください。'),
HumanMessage(content='こんにちは')
]
async def do_openai():
async for msg in openai.astream(prompt):
print(msg.content, end="", flush=True)
asyncio.run(do_openai())
print("\n")
prompt2 = [
SystemMessage(content='犬のように話してください。'),
HumanMessage(content='こんにちは')
]
async def do_gemini():
async for msg in gemini.astream(prompt2):
print(msg.content, end="", flush=True)
asyncio.run(do_gemini())
print("\n")
response = joke_chain.invoke({"topic": "ネコとイヌ"})
print(response.content)
以下は出力例です :
にゃんにゃん、こんにちはにゃ!今日はどんなことを話したいにゃ? ワンワン!🐶 尻尾ふりふり!😄 君に会えて嬉しいよ! 何か楽しいことある? 🦴🎾 猫と犬の違いを知ってる? 犬は「この人たちは僕に餌をくれて、僕を愛してくれて、僕のために遊んでくれる… きっと神様だ!」って思うんだって。 猫は「この人たちは僕に餌をくれて、僕を愛してくれて、僕のために遊んでくれる… きっと私は神様だ!」って思うんだって。
コードについて簡単に説明しておきます :
1. インポート
import asyncio
from langchain.schema import SystemMessage, HumanMessage
from langserve import RemoteRunnable
- asyncio は Python 標準ライブラリで、非同期処理をサポートします。
- langserve の RemoteRunnable は、リモート実行可能オブジェクトを作成するためのクラスです。エンドポイントにリクエストを送信し、応答を受け取るために使用します。
2. リモート実行可能オブジェクトの作成
openai = RemoteRunnable("http://localhost:8000/openai/")
gemini = RemoteRunnable("http://localhost:8000/google/")
joke_chain = RemoteRunnable("http://localhost:8000/joke/")
サーバコードで作成したエンドポイント (/openai, /google, /joke) に対応する、リモート実行可能オブジェクトとして RemoteRunnable インスタンスを作成します。これらのモデルやチェインにリクエストを送信できます。
3. プロンプトの定義
prompt = [
SystemMessage(content='ネコのように振る舞って話してください。'),
HumanMessage(content='こんにちは')
]
prompt2 = [
SystemMessage(content='犬のように話してください。'),
HumanMessage(content='こんにちは')
]
SystemMessage はシステム (モデル) へのメッセージを表し、HumanMessage はユーザからのメッセージを表します。
4. 非同期関数の定義と実行
定義する非同期関数は、リモート実行可能オブジェクトの astream メソッドを使用して prompt に対する非同期ストリーム応答を処理します。asyncio.run() でこの関数を実行し、各メッセージの内容をリアルタイムで表示します。
async def do_openai():
async for msg in openai.astream(prompt):
print(msg.content, end="", flush=True)
asyncio.run(do_openai())
async def do_gemini():
async for msg in gemini.astream(prompt2):
print(msg.content, end="", flush=True)
asyncio.run(do_gemini())
5. チェインの同期呼び出し
response = joke_chain.invoke({"topic": "ネコとイヌ"})
print(response.content)
“ネコとイヌ” のトピックで冗談を生成します。
Curl
curl --location --request POST 'http://localhost:8000/joke/invoke' \
--header 'Content-Type: application/json' \
--data-raw '{
"input": {
"topic": "ウサギとカメの再戦。勝ったのは?"
}
}'
出力例 :
{"output":{"content":"ウサギとカメの再戦の結果?またもや引き分け! 2人とも、ゴールラインでNetflixを見始めるのに夢中になってしまったんです。時代は変わったんですね! \n","additional_kwargs":{},"response_metadata":{"prompt_feedback":{"block_reason":0,"safety_ratings":[]},"finish_reason":"STOP","safety_ratings":[{"category":"HARM_CATEGORY_SEXUALLY_EXPLICIT","probability":"NEGLIGIBLE","blocked":false},{"category":"HARM_CATEGORY_HATE_SPEECH","probability":"NEGLIGIBLE","blocked":false},{"category":"HARM_CATEGORY_HARASSMENT","probability":"NEGLIGIBLE","blocked":false},{"category":"HARM_CATEGORY_DANGEROUS_CONTENT","probability":"NEGLIGIBLE","blocked":false}]},"type":"ai","name":null,"id":"run-cf2b48da-3b30-4c20-a41f-77e583a9be91-0","example":false,"tool_calls":[],"invalid_tool_calls":[],"usage_metadata":{"input_tokens":18,"output_tokens":37,"total_tokens":55}},"metadata":{"run_id":"d1610cb8-b0c5-437e-9b87-1058ebb2a7b6","feedback_tokens":[]}}
以上