HuggingFace TRL 0.5 : Transformer 強化学習 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/12/2023 (v0.5.0)
* 本ページは、huggingface/trl の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
HuggingFace TRL 0.5 : Transformer 強化学習
![]()
強化学習そ使用したフルスタック transformer 言語モデル。
What is it?

trl は、教師あり微調整 (SFT, Supervised Fine-tuning) ステップ, 報酬モデリング (RM, Reward Modeling) ステップから近接ポリシー最適化 (PPO, Proximal Policy Optimization) ステップまで、強化学習を使用して transformer 言語モデルを訓練するツールのセットを提供するフルスタックのライブラリです。このライブラリは 🤗 Hugging Face による transformers ライブラリの上に構築されています。そのため、事前訓練済み言語モデルは transformers により直接ロードできます。現時点で殆どのデコーダ・アーキテクチャとエンコーダデコーダ・アーキテクチャがサポートされています。サンプルのコードスニペットとこれらのツールを実行する方法についてはドキュメントか examples/ フォルダを参照してください。
ハイライト
- SFTTrainer : カスタムデータセットで言語モデルやアダプターを簡単に微調整するための transformers トレーナーの軽量でフレンドリーなラッパー。
- RewardTrainer : 人間の好みのために言語モデルを簡単に微調整するための transformers トレーナーの軽量ラッパー (報酬モデリング)。
- PPOTrainer : 言語モデルを最適化するために (query, response, reward) トリプレットだけを必要とする言語モデルのための PPO トレーナー
- AutoModelForCausalLMWithValueHead & AutoModelForSeq2SeqLMWithValueHead : 強化学習で値関数として使用できる、各トークンに対する追加のスカラー出力を持つ transformer モデル。
- Examples : BERT センチメント分類器による肯定的な映画レビューを生成する GPT2 を訓練する、アダプターだけを使用する完全な RLHF、有害度が低くなるように GPT-J を訓練する、Stack-Llama サンプル 等。
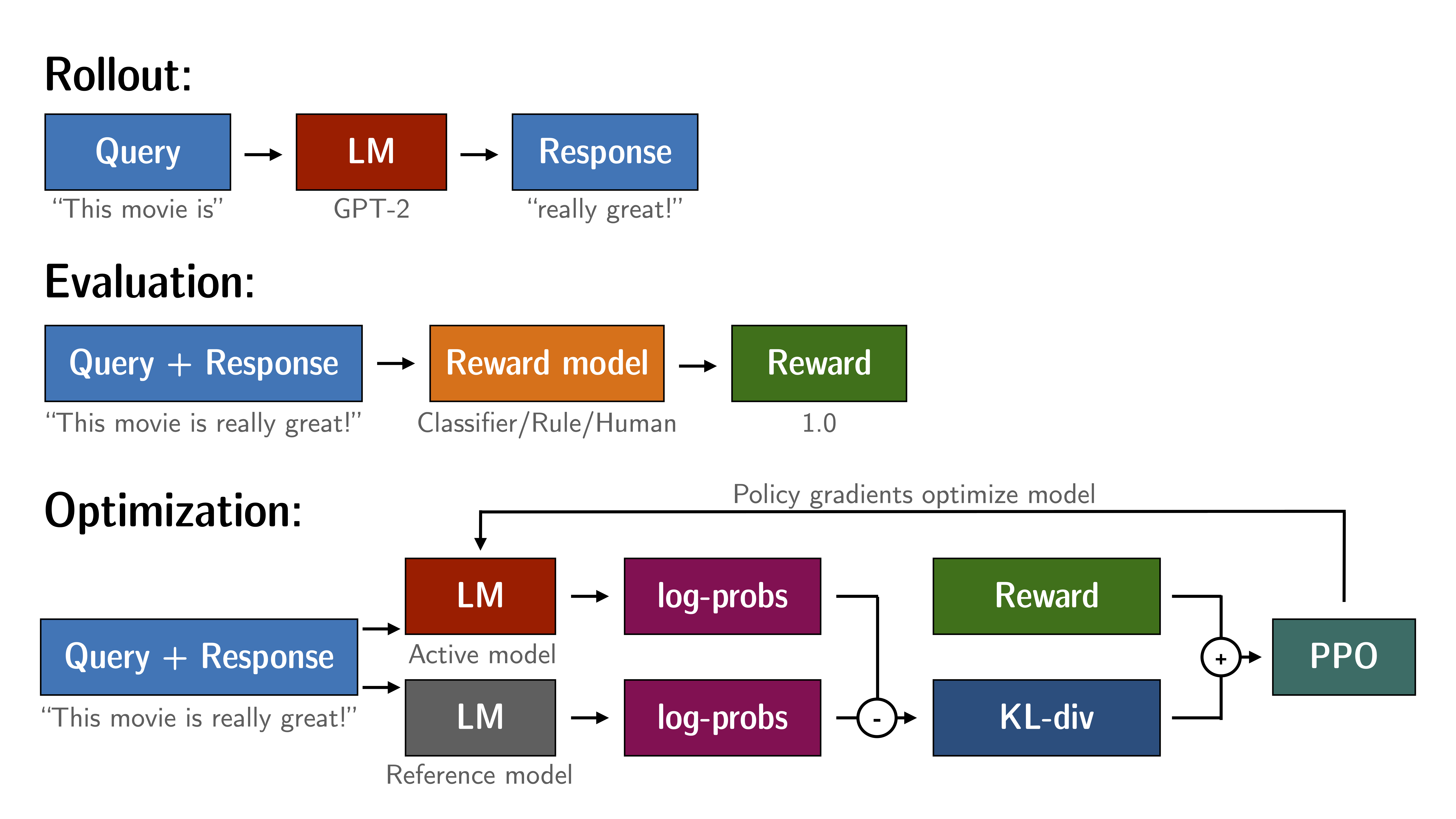
どのように PPO が機能するか
PPO による言語モデルの微調整はおよそ 3 つのステップから構成されます :
- ロールアウト (Rollout) : 言語モデルはセンテンスの開始となるようなクエリーに基づいてレスポンスまたは継続 (continuation) を返します。
- 評価 (Evaluation) : クエリーとレスポンスは関数、モデル、人間のフィードバックまたはそれらの組み合わせにより評価されます。重要なことはこのプロセスは各クエリー/レスポンスのペアに対してスカラー値を生成する必要があることです。
- 最適化 : これは最も複雑なパートです。最適化ステップでは、クエリー/レスポンスのペアはシークエンスのトークンの対数確率を計算するために使用されます。これは訓練されたモデルと、通常は微調整する前に事前訓練された参照モデルにより行われます。2 つの出力の間の KL-ダイバージェンスは、生成されたレスポンスが参照言語モデルから大きく外れないことを確実にするために、追加の報酬信号として使用されます。それからアクティブな言語モデルは PPO で訓練されます。
This process is illustrated in the sketch below:
Figure: Sketch of the workflow.
インストール
Python パッケージ
Install the library with pip:
pip install trl
How to use
SFTTrainer
これはライブラリの SFTTrainer を使用する方法の基本的なサンプルです。SFTTrainer は、カスタムデータセットで言語モデルやアダプターを簡単に微調整するための transformers トレーナーの軽量でフレンドリーなラッパーです。
# imports
from datasets import load_dataset
from trl import SFTTrainer
# get dataset
dataset = load_dataset("imdb", split="train")
# get trainer
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
# train
trainer.train()
RewardTrainer
これはライブラリの RewardTrainer を使用する方法の基本的なサンプルです。RewardTrainer は、カスタム preference データセット上で報酬モデルやアダプターを簡単に微調整するための transformers トレーナーのラッパーです。
# imports
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer
# load model and dataset - dataset needs to be in a specific format
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
...
# load trainer
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
)
# train
trainer.train()
PPOTrainer
これはライブラリの PPOTrainer を使用する方法の基本的なサンプルです。クエリーに基づいて言語モデルはレスポンスを作成し、そして評価されます。評価はループ内の人間か別のモデルの出力である可能性があります。
# imports
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch
# get models
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = create_reference_model(model)
tokenizer = AutoTokenizer.from_pretrained('gpt2')
# initialize trainer
ppo_config = PPOConfig(
batch_size=1,
)
# encode a query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
# get model response
response_tensor = respond_to_batch(model, query_tensor)
# create a ppo trainer
ppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0)]
# train model for one step with ppo
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
Citation
(訳注: 原文 参照)
以上