Paella : ノートブック : サンプリング (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 12/11/2022 (v2.7.0)
* 本ページは、dome272/Paella の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP

Paella : ノートブック : サンプリング
Paella レポジトリとともに OpenCLIP も使用します。
!nvidia-smi
Thu Dec 15 03:40:04 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 29C P0 53W / 400W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
※ 訳注 : GPU メモリは 15GB では不足します。
!pip install einops rudalle open_clip_torch git+https://github.com/pabloppp/pytorch-tools
!git clone https://github.com/dome272/Paella
モデルのダウンロード
最初のコマンドは標準モデルをダウンロードします、これはテキスト埋め込み上で訓練されました。
2 番目のコマンドは画像埋め込み上で微調整されたモデルを追加でダウンロードします、これは画像のバリエーションを生成するのに役立ちます。
!curl -L -s -o ./model_600000.pt 'https://drive.google.com/uc?id=1ACIb2nrZk_jQID8bP9qYKkNZVldM94zw&confirm=t' # Text-Model
!curl -L -s -o ./model_50000_img.pt 'https://drive.google.com/uc?id=1VVWPXFLdI18TXhqlYmfMNT41Suz9pJr8&confirm=t' # Finetuned Image-Model
セットアップコード
必要なモジュールをインポートします :
import os
import time
import torch
from torch import nn
import torchvision
import matplotlib.pyplot as plt
from tqdm import tqdm
from PIL import Image
import requests
from io import BytesIO
from Paella.modules import DenoiseUNet
import open_clip
from open_clip import tokenizer
from rudalle import get_vae
from einops import rearrange
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
サンプリング関数 sample() とともに各種ユティリティ関数を定義します :
def showmask(mask):
plt.axis("off")
plt.imshow(torch.cat([
torch.cat([i for i in mask[0:1].cpu()], dim=-1),
], dim=-2).cpu())
plt.show()
def showimages(imgs, **kwargs):
plt.figure(figsize=(kwargs.get("width", 32), kwargs.get("height", 32)))
plt.axis("off")
plt.imshow(torch.cat([
torch.cat([i for i in imgs], dim=-1),
], dim=-2).permute(1, 2, 0).cpu())
plt.show()
def saveimages(imgs, name, **kwargs):
name = name.replace(" ", "_").replace(".", "")
path = os.path.join("outputs", name + ".jpg")
while os.path.exists(path):
base, ext = path.split(".")
num = base.split("_")[-1]
if num.isdigit():
num = int(num) + 1
base = "_".join(base.split("_")[:-1])
else:
num = 0
path = base + "_" + str(num) + "." + ext
torchvision.utils.save_image(imgs, path, **kwargs)
def log(t, eps=1e-20):
return torch.log(t + eps)
def gumbel_noise(t):
noise = torch.zeros_like(t).uniform_(0, 1)
return -log(-log(noise))
def gumbel_sample(t, temperature=1., dim=-1):
return ((t / max(temperature, 1e-10)) + gumbel_noise(t)).argmax(dim=dim)
def sample(model, c, x=None, mask=None, T=12, size=(32, 32), starting_t=0, temp_range=[1.0, 1.0], typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=-1, renoise_steps=11, renoise_mode='start'):
with torch.inference_mode():
r_range = torch.linspace(0, 1, T+1)[:-1][:, None].expand(-1, c.size(0)).to(c.device)
temperatures = torch.linspace(temp_range[0], temp_range[1], T)
preds = []
if x is None:
x = torch.randint(0, model.num_labels, size=(c.size(0), *size), device=c.device)
elif mask is not None:
noise = torch.randint(0, model.num_labels, size=(c.size(0), *size), device=c.device)
x = noise * mask + (1-mask) * x
init_x = x.clone()
for i in range(starting_t, T):
if renoise_mode == 'prev':
prev_x = x.clone()
r, temp = r_range[i], temperatures[i]
logits = model(x, c, r)
if classifier_free_scale >= 0:
logits_uncond = model(x, torch.zeros_like(c), r)
logits = torch.lerp(logits_uncond, logits, classifier_free_scale)
x = logits
x_flat = x.permute(0, 2, 3, 1).reshape(-1, x.size(1))
if typical_filtering:
x_flat_norm = torch.nn.functional.log_softmax(x_flat, dim=-1)
x_flat_norm_p = torch.exp(x_flat_norm)
entropy = -(x_flat_norm * x_flat_norm_p).nansum(-1, keepdim=True)
c_flat_shifted = torch.abs((-x_flat_norm) - entropy)
c_flat_sorted, x_flat_indices = torch.sort(c_flat_shifted, descending=False)
x_flat_cumsum = x_flat.gather(-1, x_flat_indices).softmax(dim=-1).cumsum(dim=-1)
last_ind = (x_flat_cumsum < typical_mass).sum(dim=-1)
sorted_indices_to_remove = c_flat_sorted > c_flat_sorted.gather(1, last_ind.view(-1, 1))
if typical_min_tokens > 1:
sorted_indices_to_remove[..., :typical_min_tokens] = 0
indices_to_remove = sorted_indices_to_remove.scatter(1, x_flat_indices, sorted_indices_to_remove)
x_flat = x_flat.masked_fill(indices_to_remove, -float("Inf"))
# x_flat = torch.multinomial(x_flat.div(temp).softmax(-1), num_samples=1)[:, 0]
x_flat = gumbel_sample(x_flat, temperature=temp)
x = x_flat.view(x.size(0), *x.shape[2:])
if mask is not None:
x = x * mask + (1-mask) * init_x
if i < renoise_steps:
if renoise_mode == 'start':
x, _ = model.add_noise(x, r_range[i+1], random_x=init_x)
elif renoise_mode == 'prev':
x, _ = model.add_noise(x, r_range[i+1], random_x=prev_x)
else: # 'rand'
x, _ = model.add_noise(x, r_range[i+1])
preds.append(x.detach())
return preds
DenoiseUNet をインスタンス作成して重みをロードします。OpenCLIP モデルも使用します :
os.makedirs("outputs", exist_ok=True)
vqmodel = get_vae().to(device)
vqmodel.eval().requires_grad_(False)
clip_model, _, _ = open_clip.create_model_and_transforms('ViT-g-14', pretrained='laion2b_s12b_b42k')
clip_model = clip_model.to(device).eval().requires_grad_(False)
clip_preprocess = torchvision.transforms.Compose([
torchvision.transforms.Resize(224, interpolation=torchvision.transforms.InterpolationMode.BICUBIC),
torchvision.transforms.Normalize(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711)),
])
preprocess = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
# torchvision.transforms.CenterCrop(256),
torchvision.transforms.ToTensor(),
])
def encode(x):
return vqmodel.model.encode((2 * x - 1))[-1][-1]
def decode(img_seq, shape=(32,32)):
img_seq = img_seq.view(img_seq.shape[0], -1)
b, n = img_seq.shape
one_hot_indices = torch.nn.functional.one_hot(img_seq, num_classes=vqmodel.num_tokens).float()
z = (one_hot_indices @ vqmodel.model.quantize.embed.weight)
z = rearrange(z, 'b (h w) c -> b c h w', h=shape[0], w=shape[1])
img = vqmodel.model.decode(z)
img = (img.clamp(-1., 1.) + 1) * 0.5
return img
state_dict = torch.load("./model_600000.pt", map_location=device)
# state_dict = torch.load("./models/f8_img_40000.pt", map_location=device)
model = DenoiseUNet(num_labels=8192).to(device)
model.load_state_dict(state_dict)
model.eval().requires_grad_()
print()
Working with z of shape (1, 256, 32, 32) = 262144 dimensions. /usr/local/lib/python3.8/dist-packages/huggingface_hub/file_download.py:594: FutureWarning: `cached_download` is the legacy way to download files from the HF hub, please consider upgrading to `hf_hub_download` warnings.warn( Downloading: 100% 346M/346M [00:04<00:00, 57.9MB/s] vae --> ready Downloading: 100% 5.47G/5.47G [04:59<00:00, 18.8MB/s]
テキスト条件付き
プロンプトとして "highly detailed photograph of darth vader. artstation" を使用します :
mode = "text"
batch_size = 6
text = "highly detailed photograph of darth vader. artstation"
latent_shape = (32, 32)
tokenized_text = tokenizer.tokenize([text] * batch_size).to(device)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
clip_embeddings = clip_model.encode_text(tokenized_text)
s = time.time()
sampled = sample(model, clip_embeddings, T=12, size=latent_shape, starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=5, renoise_steps=11,
renoise_mode="start")
print(time.time() - s)
sampled = decode(sampled[-1], latent_shape)
showimages(sampled)
saveimages(sampled, mode + "_" + text, nrow=len(sampled))


潜在空間補間
mode = "interpolation"
text = "surreal painting of a yellow tulip. artstation"
text2 = "surreal painting of a red tulip. artstation"
text_encoded = tokenizer.tokenize([text]).to(device)
text2_encoded = tokenizer.tokenize([text2]).to(device)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
clip_embeddings = clip_model.encode_text(text_encoded).float()
clip_embeddings2 = clip_model.encode_text(text2_encoded).float()
l = torch.linspace(0, 1, 10).to(device)
embeddings = []
for i in l:
lerp = torch.lerp(clip_embeddings, clip_embeddings2, i)
embeddings.append(lerp)
embeddings = torch.cat(embeddings)
s = time.time()
sampled = sample(model, embeddings, T=12, size=(32, 32), starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=4, renoise_steps=11)
print(time.time() - s)
sampled = decode(sampled[-1])
showimages(sampled)
saveimages(sampled, mode + "_" + text + "_" + text2, nrow=len(sampled))
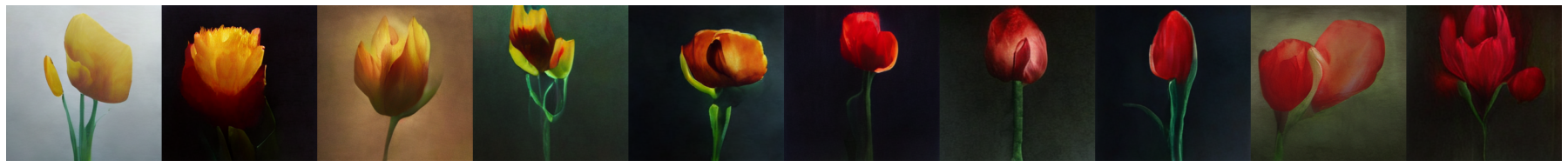
mode = "interpolation"
text = "High quality front portrait photo of a tiger."
text2 = "High quality front portrait photo of a dog."
text_encoded = tokenizer.tokenize([text]).to(device)
text2_encoded = tokenizer.tokenize([text2]).to(device)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
clip_embeddings = clip_model.encode_text(text_encoded).float()
clip_embeddings2 = clip_model.encode_text(text2_encoded).float()
l = torch.linspace(0, 1, 10).to(device)
s = time.time()
outputs = []
for i in l:
# lerp = torch.lerp(clip_embeddings, clip_embeddings2, i)
low, high = clip_embeddings, clip_embeddings2
low_norm = low/torch.norm(low, dim=1, keepdim=True)
high_norm = high/torch.norm(high, dim=1, keepdim=True)
omega = torch.acos((low_norm*high_norm).sum(1)).unsqueeze(1)
so = torch.sin(omega)
lerp = (torch.sin((1.0-i)*omega)/so)*low + (torch.sin(i*omega)/so) * high
with torch.random.fork_rng():
torch.random.manual_seed(32)
sampled = sample(model, lerp, T=12, size=(32, 32), starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=5, renoise_steps=11)
outputs.append(sampled[-1])
print(time.time() - s)
sampled = torch.cat(outputs)
sampled = decode(sampled)
showimages(sampled)
saveimages(sampled, mode + "_" + text + "_" + text2, nrow=len(sampled))

マルチ条件付き
条件を調整してより多くのキャプションを追加することもできます。条件の構造は [[caption_1, end_token_1], [caption_2, end_token_2], ...] です。下のサンプルでは、最初のキャプションがトークン 20 まで潜在的画像を水平に満たし、それからトークン 60 まで次のキャプションが来ます、等々。
mode = "multiconditioning"
batch_size = 4
latent_shape = (32, 100)
conditions = [
["an oil painting of a lighthouse standing on a hill", 20],
["an oil painting of a majestic boat sailing on the water during a storm. front view", 60],
["an oil painting of a majestic castle standing by the water", 100],
]
clip_embedding = torch.zeros(batch_size, 1024, *latent_shape).to(device)
last_pos = 0
for text, pos in conditions:
tokenized_text = tokenizer.tokenize([text] * batch_size).to(device)
part_clip_embedding = clip_model.encode_text(tokenized_text).float()[:, :, None, None]
print(f"{last_pos}:{pos}={text}")
clip_embedding[:, :, :, last_pos:pos] = part_clip_embedding
last_pos = pos
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
sampled = sample(model, clip_embedding, T=12, size=latent_shape, starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=5, renoise_steps=11,
renoise_mode="start")
sampled = decode(sampled[-1], latent_shape)
showimages(sampled)
saveimages(sampled, mode + "_" + ":".join(list(map(lambda x: x[0], conditions))), nrow=batch_size)

batch_size = 4
latent_shape = (32, 32)
text_a = "a cute portrait of a dog"
text_b = "a cute portrait of a cat"
mode = "vertical"
# mode = "horizontal"
text = tokenizer.tokenize([text_a, text_b] * batch_size).to(device)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
clip_embeddings = clip_model.encode_text(text).float()[:, :, None, None].expand(-1, -1, latent_shape[0], latent_shape[1])
if mode == 'vertical':
interp_mask = torch.linspace(0, 1, latent_shape[0], device=device)[None, None, :, None].expand(batch_size, 1, -1, latent_shape[1])
else:
interp_mask = torch.linspace(0, 1, latent_shape[1], device=device)[None, None, None, :].expand(batch_size, 1, latent_shape[0], -1)
# LERP
clip_embeddings = clip_embeddings[0::2] * (1-interp_mask) + clip_embeddings[1::2] * interp_mask
# # SLERP
# low, high = clip_embeddings[0::2], clip_embeddings[1::2]
# low_norm = low/torch.norm(low, dim=1, keepdim=True)
# high_norm = high/torch.norm(high, dim=1, keepdim=True)
# omega = torch.acos((low_norm*high_norm).sum(1)).unsqueeze(1)
# so = torch.sin(omega)
# clip_embeddings = (torch.sin((1.0-interp_mask)*omega)/so)*low + (torch.sin(interp_mask*omega)/so) * high
sampled = sample(model, clip_embeddings, T=12, size=latent_shape, starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=5, renoise_steps=11,
renoise_mode="start")
sampled = decode(sampled[-1], latent_shape)
showimages(sampled)


画像のロード : ディスク or Web
images = preprocess(Image.open("path_to_image")).unsqueeze(0).expand(4, -1, -1, -1).to(device)[:, :3]
showimages(images)
url = "https://media.istockphoto.com/id/1193591781/photo/obedient-dog-breed-welsh-corgi-pembroke-sitting-and-smiles-on-a-white-background-not-isolate.jpg?s=612x612&w=0&k=20&c=ZDKTgSFQFG9QvuDziGsnt55kvQoqJtIhrmVRkpYqxtQ="
# url = "https://upload.wikimedia.org/wikipedia/commons/thumb/e/ea/Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg/1200px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg"
response = requests.get(url)
img = Image.open(BytesIO(response.content)).convert("RGB")
images = preprocess(img).unsqueeze(0).expand(4, -1, -1, -1).to(device)[:, :3]
showimages(images)

インペインティング
mode = "inpainting"
text = "a delicious spanish paella"
tokenized_text = tokenizer.tokenize([text] * images.shape[0]).to(device)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
# clip_embeddings = clip_model.encode_image(clip_preprocess(images)).float() # clip_embeddings = clip_model.encode_text(text).float()
clip_embeddings = clip_model.encode_text(tokenized_text).float()
encoded_tokens = encode(images)
latent_shape = encoded_tokens.shape[1:]
mask = torch.zeros_like(encoded_tokens)
mask[:,5:28,5:28] = 1
sampled = sample(model, clip_embeddings, x=encoded_tokens, mask=mask, T=12, size=latent_shape, starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=6, renoise_steps=11)
sampled = decode(sampled[-1], latent_shape)
showimages(images[0:1], height=10, width=10)
showmask(mask[0:1])
showimages(sampled, height=16, width=16)
saveimages(torch.cat([images[0:1], sampled]), mode + "_" + text, nrow=images.shape[0]+1)



アウトペインティング
mode = "outpainting"
size = (40, 64)
top_left = (0, 16)
text = "black & white photograph of a rocket from the bottom."
tokenized_text = tokenizer.tokenize([text] * images.shape[0]).to(device)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
# clip_embeddings = clip_model.encode_image(clip_preprocess(images)).float()
clip_embeddings = clip_model.encode_text(tokenized_text).float()
encoded_tokens = encode(images)
canvas = torch.zeros((images.shape[0], *size), dtype=torch.long).to(device)
canvas[:, top_left[0]:top_left[0]+encoded_tokens.shape[1], top_left[1]:top_left[1]+encoded_tokens.shape[2]] = encoded_tokens
mask = torch.ones_like(canvas)
mask[:, top_left[0]:top_left[0]+encoded_tokens.shape[1], top_left[1]:top_left[1]+encoded_tokens.shape[2]] = 0
sampled = sample(model, clip_embeddings, x=canvas, mask=mask, T=12, size=size, starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=4, renoise_steps=11)
sampled = decode(sampled[-1], size)
showimages(images[0:1], height=10, width=10)
showmask(mask[0:1])
showimages(sampled, height=16, width=16)
saveimages(sampled, mode + "_" + text, nrow=images.shape[0])
構造的モーフィング
mode = "morphing"
max_steps = 24
init_step = 8
text = "A fox posing for a photo. stock photo. highly detailed. 4k"
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
# images = preprocess(Image.open("data/city sketch.png")).unsqueeze(0).expand(4, -1, -1, -1).to(device)[:, :3]
latent_image = encode(images)
latent_shape = latent_image.shape[-2:]
r = torch.ones(latent_image.size(0), device=device) * (init_step/max_steps)
noised_latent_image, _ = model.add_noise(latent_image, r)
tokenized_text = tokenizer.tokenize([text] * images.size(0)).to(device)
clip_embeddings = clip_model.encode_text(tokenized_text).float()
sampled = sample(model, clip_embeddings, x=noised_latent_image, T=max_steps, size=latent_shape, starting_t=init_step, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=6, renoise_steps=max_steps-1,
renoise_mode="prev")
sampled = decode(sampled[-1], latent_shape)
showimages(sampled)
showimages(images)
saveimages(torch.cat([images[0:1], sampled]), mode + "_" + text, nrow=images.shape[0]+1)

画像バリエーション
Note : 画像バリエーションが正しく動作するためには、画像埋め込み上で微調整されたチェックポイントをダウンロードする必要があります。
clip_preprocess = torchvision.transforms.Compose([
torchvision.transforms.Resize((224, 224), interpolation=torchvision.transforms.InterpolationMode.BICUBIC),
torchvision.transforms.Normalize(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711)),
])
latent_shape = (32, 32)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
clip_embeddings = clip_model.encode_image(clip_preprocess(images)).float() # clip_embeddings = clip_model.encode_text(text).float()
sampled = sample(model, clip_embeddings, T=12, size=latent_shape, starting_t=0, temp_range=[1.0, 1.0],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=5, renoise_steps=11)
sampled = decode(sampled[-1], latent_shape)
showimages(images)
showimages(sampled)
実験的: コンセプト学習
def text_encode(x, clip_model, insertion_index):
# x = x.type(clip_model.dtype)
x = x + clip_model.positional_embedding
x = x.permute(1, 0, 2) # NLD -> LND
x = clip_model.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = clip_model.ln_final(x)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), insertion_index] @ clip_model.text_projection
return x
from torch.optim import AdamW
batch_size = 1
asteriks_emb = clip_model.token_embedding(tokenizer.tokenize(["*"]).to(device))[0][1]
context_word = torch.randn(batch_size, 1, asteriks_emb.shape[-1]).to(device)
context_word.requires_grad_(True)
optim = AdamW(params=[context_word], lr=0.1)
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
import requests
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
_preprocess = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(256),
torchvision.transforms.ToTensor(),
])
urls = [
"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcStVHtFcMqIP4xuDYn8n_FzPDKjPtP_iTSbOQ&usqp=CAU",
"https://i.insider.com/58d919eaf2d0331b008b4bbd?width=700",
"https://media.cntraveler.com/photos/5539216cab60aad20f3f3aaa/16:9/w_2560%2Cc_limit/eiffel-tower-paris-secret-apartment.jpg",
"https://static.independent.co.uk/s3fs-public/thumbnails/image/2014/03/25/12/eiffel.jpg?width=1200"
]
images = []
for url in urls:
response = requests.get(url)
img = Image.open(BytesIO(response.content))
images.append(_preprocess(img))
data = torch.stack(images)
dataset = DataLoader(TensorDataset(data), batch_size=1, shuffle=True)
loader = iter(dataset)
steps = 100
total_loss = 0
total_acc = 0
pbar = tqdm(range(steps))
for i in pbar:
try:
images = next(loader)[0]
except StopIteration:
loader = iter(dataset)
images = next(loader)[0]
images = images.to(device)
text = "a photo of *"
tokenized_text = tokenizer.tokenize([text]).to(device)
insertion_index = tokenized_text.argmax(dim=-1)
neutral_text_encoded = clip_model.token_embedding(tokenized_text)
insertion_idx = torch.where(neutral_text_encoded == asteriks_emb)[1].unique()
neutral_text_encoded[:, insertion_idx, :] = context_word
clip_embeddings = text_encode(neutral_text_encoded, clip_model, insertion_index)
with torch.no_grad():
image_indices = encode(images)
r = torch.rand(images.size(0), device=device)
noised_indices, mask = model.add_noise(image_indices, r)
# with torch.autocast(device_type="cuda"):
pred = model(noised_indices, clip_embeddings, r)
loss = criterion(pred, image_indices)
loss.backward()
optim.step()
optim.zero_grad()
acc = (pred.argmax(1) == image_indices).float() # .mean()
acc = acc.mean()
total_loss += loss.item()
total_acc += acc.item()
pbar.set_postfix({"total_loss": total_loss / (i+1), "total_acc": total_acc / (i+1)})
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
sampled = sample(model, clip_embeddings.expand(4, -1), T=12, size=(32, 32), starting_t=0, temp_range=[1., 1.],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=4, renoise_steps=11)
sampled = decode(sampled[-1])
plt.figure(figsize=(32, 32))
plt.axis("off")
plt.imshow(torch.cat([
torch.cat([i for i in images.expand(4, -1, -1, -1).cpu()], dim=-1),
torch.cat([i for i in sampled.cpu()], dim=-1),
], dim=-2).permute(1, 2, 0).cpu())
plt.show()

text = "* at night"
tokenized_text = tokenizer.tokenize([text]).to(device)
insertion_index = tokenized_text.argmax(dim=-1)
neutral_text_encoded = clip_model.token_embedding(tokenized_text)
insertion_idx = torch.where(neutral_text_encoded == asteriks_emb)[1].unique()
neutral_text_encoded[:, insertion_idx, :] = context_word
clip_embeddings = text_encode(neutral_text_encoded, clip_model, insertion_index)
with torch.inference_mode():
with torch.autocast(device_type="cuda"):
sampled = sample(model, clip_embeddings.expand(4, -1), T=12, size=(32, 32), starting_t=0, temp_range=[1., 1.],
typical_filtering=True, typical_mass=0.2, typical_min_tokens=1, classifier_free_scale=4, renoise_steps=11)
sampled = decode(sampled[-1])
plt.figure(figsize=(32, 32))
plt.axis("off")
plt.imshow(torch.cat([
torch.cat([i for i in images.expand(4, -1, -1, -1).cpu()], dim=-1),
torch.cat([i for i in sampled.cpu()], dim=-1),
], dim=-2).permute(1, 2, 0).cpu())
plt.show()

以上