HuggingFace ブログ : Sentence Transformers モデルの訓練と微調整 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 12/08/2022
* 本ページは、HuggingFace Blog の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Train and Fine-Tune Sentence Transformers Models (Authors : Omar Espejel ; Published : 08/10/2022)
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
HuggingFace ブログ : Sentence Transformers モデルの訓練と微調整
Sentence Transformer モデルの訓練や再調整は利用可能なデータとターゲットタスクに極度に依存します。キーは 2 つから成ります :
- データをモデルに入力する方法を理解してそれに応じてデータセットを準備します。
- 様々な損失関数とそれらがデータセットとどのように関係するかを知ります。
このチュートリアルでは、以下を行ないます :
- Sentence Transformers モデルをゼロから作成したり Hugging Face ハブから微調整してどのように動作するかを理解します。
- データセットが持てる様々な形式を学習します。
- データセット形式に基づいて選択できる様々な損失関数をレビューします。
- モデルを訓練または微調整します。
- モデルを Hugging Face ハブで共有します。
- Sentence Transformers モデルがベストな選択ではない可能性がある場合を学習します。
Sentence Transformers モデルがどのように動作するか
Sentence Transformer モデルでは、可変長のテキスト (or 画像ピクセル) をその入力の意味を表現する固定サイズの埋め込みにマップします。埋め込みを始めるには、前のチュートリアル を調べてください。この記事はテキストにフォーカスします。
これは Sentence Transformers モデルがどのように動作するかです :
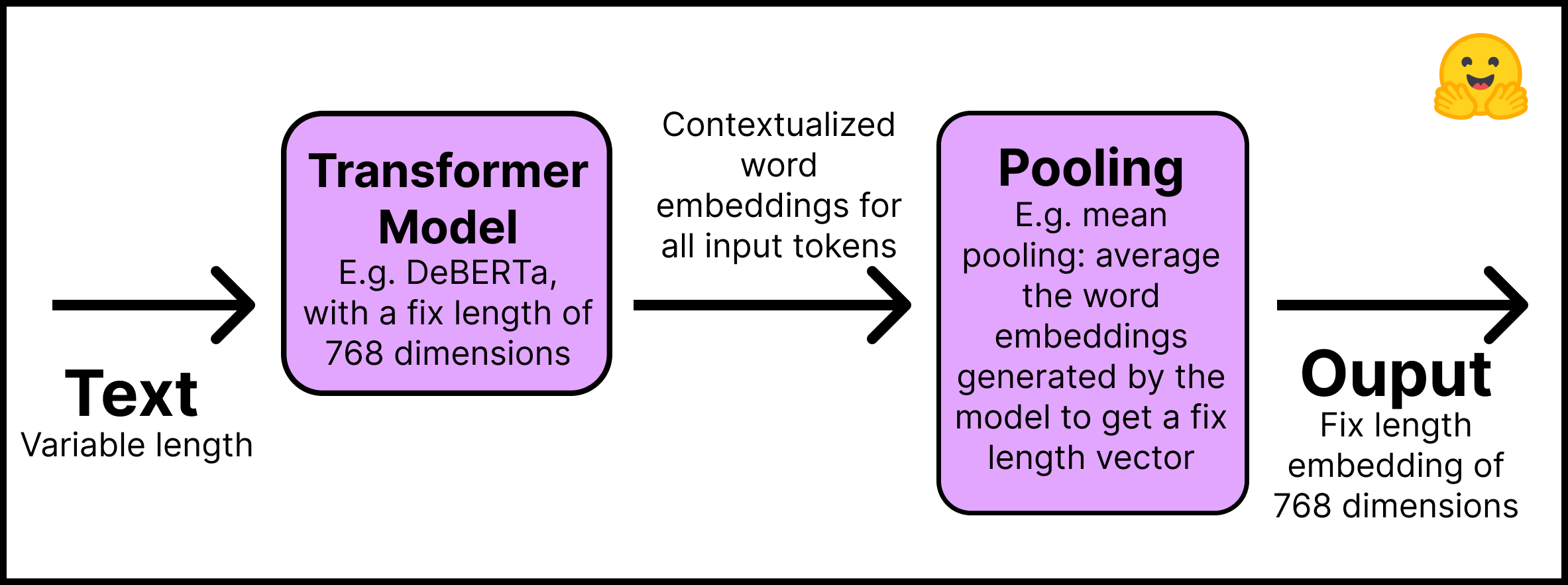
- Layer 1 – 入力テキストは Hugging Face ハブ から直接取得可能な事前訓練済み Transformer モデルに渡されます。このチュートリアルは “distilroberta-base” モデルを使用します。Transformer 出力はすべての入力トークンに対する contextualized 単語埋め込みです ; テキストの各トークンに対する埋め込みを想像してください。
- Layer 2 – 埋め込みはプーリング層を進み、テキスト全体に対する単一の固定長埋め込みを得ます。例えば、平均プーリングはモデルにより生成された埋め込みを平均化します。
この図はその過程を要約しています :
“pip install -U sentence-transformers” で Sentence Transformers ライブラリをインストールすることを忘れないでください。コードでは、この 2 つのステップは単純です :
from sentence_transformers import SentenceTransformer, models
## Step 1: 既存の言語モデルを使用します。
word_embedding_model = models.Transformer('distilroberta-base')
## Step 2: トークン埋め込みに渡るプール関数を使用します。
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
## Join steps 1 and 2 using the modules argument
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
上のコードから、Sentence Transformers モデルがモジュール、つまり連続的に実行される層のリストから構成されることがわかります。入力テキストは最初のモジュールに入り、最後の出力は最後のコンポーネントから得られます。ご覧のように単純ですが、上述のモデルは Sentence Transformers モデルの典型的なアーキテクチャです。必要であれば、追加の層を追加できます、例えば dense, bag of words そして畳み込みです。
センテンスやテキスト全体の埋め込みを作成するために、何故 BERT や Roberta のようなそのまま利用可能な Transformer モデルを使わないのでしょうか?少なくとも 2 つの理由があります。
- 事前訓練済み Transformers は意味検索タスクを実行するために重い計算を必要とします。例えば、10,000 センテンスのコレクションで最も類似したペアを見つけることは BERT で約 5 千万の推論計算 (~65 時間) を必要とします。対照的に、BERT Sentence Transformers モデルはその時間を約 5 秒に短縮します。
- 一度訓練されると、Transformers はそのままでは貧弱なセンテンス表現を作成します。センテンス埋め込みを作成するために平均されたトークン埋め込みを使用する BERT モデルは、2014 年に開発された GloVe 埋め込みよりも 悪い性能で遂行します。
このセクションでは Sentence Transformers モデルをゼロから作成しています。既存の Sentence Transformers モデルを微調整したいのであれば、上記のステップはスキップしてそれを Hugging Face ハブからインポートできます。殆どの Sentence Transformers モデルは「センテンス類以度」タスクで見つけられます。ここでは “sentence-transformers/all-MiniLM-L6-v2” モデルをロードします :
from sentence_transformers import SentenceTransformer
model_id = "sentence-transformers/all-MiniLM-L6-v2"
model = SentenceTransformer(model_id)
Now for the most critical part: データセット形式です。
Sentence Transformers モデルの訓練のためにどのようにデータセットを準備するか
Sentence Transformers モデルを訓練するには、2 つのセンテンスがある類以度を持つことをそれに何らかの方法で伝える必要があります。そのため、データの各サンプルは、モデルが 2 つのセンテンスが似ているか異なっているかを理解することを可能にするラベルや構造を必要とします。
残念ながら、Sentence Transformers モデルを訓練するためのデータを準備する単一の方法はありません。それは貴方の目標やデータの構造に大きく依存します。最もありがちなシナリオとして、明示的なラベルを持たない場合、センテンスを取得したドキュメントのデザインからそれを導くことができます。例えば、同じレポート内の 2 つのセンテンスは異なるレポートの 2 つのセンテンスよりも比較可能 (同等) なはずです。近接するセンテンスはそうでないセンテンスよりも同等であるかもしれません。
更に、データ構造はどの損失関数を使用できるかに影響を与えます。これは次のセクションで説明されます。
この記事のための Notebook Companion は既に実装されたすべてのコードを含むことを忘れないでください。
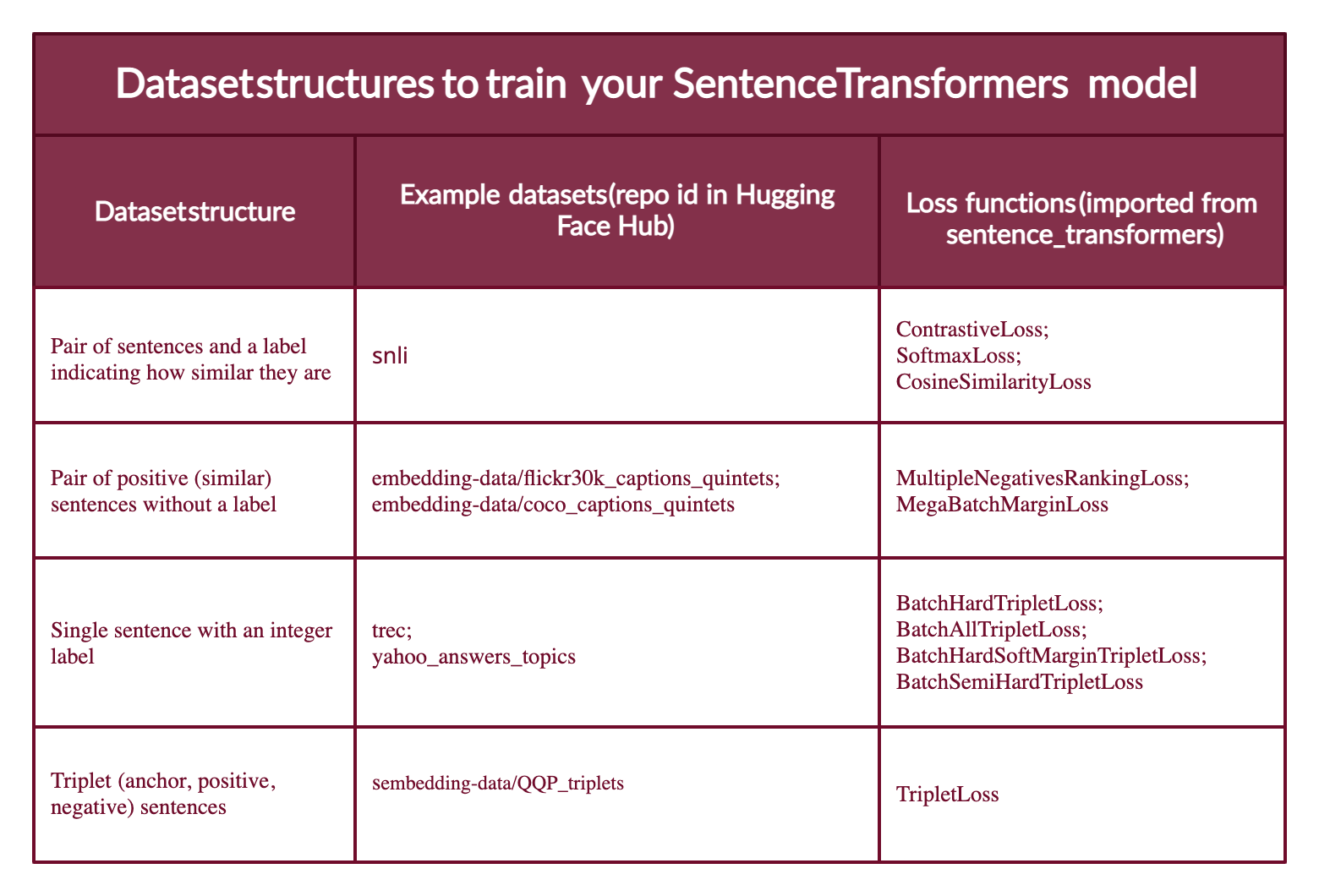
殆どのデータセット構成は 4 つの形式の一つを取ります (以下で各々の例を見ます) :
- Case 1 : このサンプルはセンテンスのペアとそれらがどの程度類似しているかを示すラベルです。ラベルは整数か浮動小数点です。このケースは元々は Natural Language Inference (NLI) のために準備されたデータセットに当てはまります、それらはセンテンスのペアと互いを推察するかを示すラベルを含むからです。
- Case 2: このサンプルはラベルなしの positive (類似した) センテンスのペアです。例えば、言い換えのペア、フルテキストとそれらの要約のペア、重複した質問のペア、(クエリー, 応答) のペア、あるいは (source_language, target_language)のペアです。Natural Language Inference データセットは entailing (含意する) センテンスのペアリングにより、このようにフォーマットすることもできます。データをこの形式にすることは素晴らしいことであり得ます、というのは Sentence Transformers モデルに対して最も使用される損失関数の一つである MultipleNegativesRankingLoss を利用できるからです。
- Case 3 : このサンプルは整数ラベルを持つセンテンスです。このデータ形式は損失関数によって簡単に 3 つのセンテンス (トリプレット) に変換されます、最初は「アンカー」で、2 番目はアンカーと同じクラスの “positive” で、3 番目は異なるクラスの “negative” です。各センテンスはそれが所属するクラスを示す整数ラベルを持ちます。
- Case 4 : このサンプルはセンテンスのためのクラスやラベルを持たないトリプレット (アンカー, positive, negative) です。
例として、このチュートリアルでは 4 番目のケースのデータセットを使用して Sentence Transformer を訓練します。それから 2 番目のケースのデータセット構成を使用して微調整します (このブログのための Notebook Companion を参照してください)。
Sentence Transformers は人間によるラベル付け (ケース 1 と 3) やテキストフォーマットから自動的に推論されたラベル (主としてケース 2 ; ケース 4 はラベルを必要としませんが、MegaBatchMarginLoss 関数が行なうように処理をしない限りは、トリプレットのデータを見つけることはより困難です) で訓練できることに注意してください。
上記のケースの各々に対して Hugging Face ハブにデータセットがあります。更に、ハブのデータセットはデータセット・プレビュー機能を持ちます、これはそれらをダウンロードする前にデータセットの構造を見ることを可能にします。ここにこれらのケースの各々に対するサンプルデータセットがあります :
- Case 1 : 2 つのセンテンス間の類以度を示すラベルを持つ (or 組み立てる) 場合には、Natural Language Inference と同じセットアップが使用できます ; 例えば {0, 1, 2} です、ここで 0 は否定 (contradiction) で 2 は含意 (entailment) です。SNLI データセット の構造をレビューしてください。
- Case 2 : Sentence Compression データセット はポジティブなペアから構成されるサンプルを持ちます。データセットがサンプル毎に 2 つ以上のポジティブなセンテンスを持つ場合、例えば、COCO Captions や Flickr30k Captions データセットのクインテット、ポジティブなペアの異なる組み合わせを持つようにサンプルをフォーマットできます。
- Case 3 : TREC データセット は各センテンスのクラスを示す整数ラベルを持ちます。Yahoo Answers Topics データセット の各サンプルは 3 つのセンテンスとトピックを示すラベルを含みます ; そのため、各サンプルは 3 つに分割できます。
- Case 4 : Quora Triplets データセット はラベルなしのトリプレット (アンカー, ポジティブ, ネガティブ) を持ちます。
次のステップはデータセットを Sentence Transformers モデルが理解できる形式に変換することです。モデルは raw 文字列のリストを受け取ることができません。各サンプルは sentence_transformers.InputExample クラスに変換してからサンプルをバッチ化してシャッフルするために torch.utils.data.DataLoader クラスに変換しなければなりません。
“pip install datasets” で Hugging Face Datasets をインストールします。そして load_dataset 関数でデータセットをインポートします :
from datasets import load_dataset
dataset_id = "embedding-data/QQP_triplets"
dataset = load_dataset(dataset_id)
このガイドはラベル付けされていないトリプレット・データセットを使用しています、上記の 4 番目のケースです。
datasets ライブラリでデータセットを調べることができます :
print(f"- The {dataset_id} dataset has {dataset['train'].num_rows} examples.")
print(f"- Each example is a {type(dataset['train'][0])} with a {type(dataset['train'][0]['set'])} as value.")
print(f"- Examples look like this: {dataset['train'][0]}")
- The embedding-data/QQP_triplets dataset has 101762 examples.
- Each example is a <class 'dict'> with a <class 'dict'> as value.
- Examples look like this: {'set': {'query': 'Why in India do we not have one on one political debate as in USA?', 'pos': ['Why can't we have a public debate between politicians in India like the one in US?'], 'neg': ['Can people on Quora stop India Pakistan debate? We are sick and tired seeing this everyday in bulk?'...]
query (アンカー) が単一センテンスを持ち、pos (ポジティブ) がセンテンスのリスト (プリントしたものは 1 つのセンテンスだけです)、そして neg (ネガティブ) は複数のセンテンスのリストを持っていることがわかります。
サンプルを InputExample 内に変換します。単純化のために、(1) embedding-data/QQP_triplets データセットのポジティブの 1 つとネガティブの 1 つだけを使用します。(2) 利用可能なサンプルの 1/2 だけを採用します。サンプルの数を増やせば遥かに良い結果を得ることができます。
from sentence_transformers import InputExample
train_examples = []
train_data = dataset['train']['set']
# For agility we only 1/2 of our available data
n_examples = dataset['train'].num_rows // 2
for i in range(n_examples):
example = train_data[i]
train_examples.append(InputExample(texts=[example['query'], example['pos'][0], example['neg'][0]]))
訓練サンプルを Dataloader に変換します。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
次のステップはデータ形式で使用できる適切な損失関数を選択することです。
Sentence Transformers モデルを訓練するための損失関数
貴方のデータが 4 つの異なる形式に入ることを覚えていますか?各々はそれに関連する異なる損失関数を持ちます。
Case 1 : センテンスのペアとそれらがどの程度類似しているかを示すラベル。損失関数は、(1) 最も近いラベルを持つセンテンスがベクトル空間で近くに、そして (2) 最も遠いラベルを持つセンテンスはできる限り遠くにくるように最適化します。損失関数はラベルの形式に依存します。それが整数であれば ContrastiveLoss か SoftmaxLoss を使用します ; それが浮動小数点であれば CosineSimilarityLoss を使用できます。
Case 2 : ラベルなしで 2 つの類似したセンテンス (2 つのポジティブ) だけを持つ場合、MultipleNegativesRankingLoss 関数を利用できます。MegaBatchMarginLoss もまた使用できます、そしてそれはサンプルをトリプレット (anchor_i, positive_i, positive_j) に変換します、ここで positive_j はネガティブとして機能します。
Case 3 : サンプルが形式 [アンカー, ポジティブ, ネガティブ] のトリプレットで各々に対して整数ラベルを持つとき、損失関数はアンカーとポジティブ・センテンスがアンカーとネガティブ・センテンスよりもベクトル空間で近くなるようにモデルを最適化します。BatchHardTripletLoss を使用できます、これは同じラベルを持つサンプルは類似していると仮定し、データが整数でラベル付け (e.g., ラベル 1, 2, 3) されることを必要とします。従って、アンカーとポジティブは同じラベルを持たなければならない一方で、ネガティブは異なるものでなければなりません。代わりに、BatchAllTripletLoss, BatchHardSoftMarginTripletLoss, あるいは BatchSemiHardTripletLoss を使用できます。それらの違いはこのチュートリアルの範囲を越えますが、Sentence Transformers ドキュメントでレビューできます。
Case 4 : トリプレットの各センテンスに対するラベルを持たない場合、TripletLoss を使用するべきです。この損失はアンカーとポジティブセンテンスの間の距離を最小化する一方で、アンカーとネガティブセンテンスの間の距離を最大化します。
この図は様々なタイプのデータセット形式、ハブのサンプルデータセット、そして適切な損失関数を要約しています。
最も難しいパートは概念的に適切な損失関数を選択することです。コードでは、2 行しかありません :
from sentence_transformers import losses
train_loss = losses.TripletLoss(model=model)
データセットが望ましい形式にあり、適切な損失関数が準備できれば、Sentence Transformers の適合と訓練は簡単です。
Sentence Transformer モデルをどのように訓練または微調整するか
「SentenceTransformers は貴方自身のセンテンス / テキスト埋め込みモデルを微調整することを簡単にするように設計されました。それは、特定のタスクに対して埋め込みを調整するために組み合わせることができる殆どのビルディングブロックを提供しています。」- Sentence Transformers ドキュメント。
これは訓練または再調整がどのようなものかです :
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=10)
既存の Sentence Transformers モデルを微調整している場合 (Notebook Companion 参照)、それから fit メソッドを直接呼び出せることを覚えておいてください。これが新しい Sentence Transformers モデルである場合には、最初にそれを “How Sentence Transformers models work” セクションで行ったように定義する必要があります。
That’s it; you have a new or improved Sentence Transformers model! それを Hugging Face ハブで共有したいですか?
最初に、Hugging Face ハブにログインします。貴方の アカウント設定 で書き込みトークンを作成する必要があります。そしてログインするには 2 つのオプションがあります :
- ターミナルで huggingface-cli とタイプしてトークンを入力します。
- python ノートブックの場合、notebook_login を使用できます。
from huggingface_hub import notebook_login
notebook_login()
それから、訓練済みモデルから save_to_hub メソッドを呼び出すことでモデルを共有できます。デフォルトでは、モデルは貴方のアカウントにアップロードされます。それを organization パラメータで渡すことで organization にアップロードすることもできます。save_to_hub はモデルカード, 推論ウイジェット, サンプルコードスニペット, そして詳細を自動的に生成します。引数 train_datasets を使用してモデルを訓練するために使用したデータセットのリストをハブのモデルケードに自動的に追加できます :
model.save_to_hub(
"distilroberta-base-sentence-transformer",
organization= # Add your username
train_datasets=["embedding-data/QQP_triplets"],
)
Notebook Companion では embedding-data/sentence-compression データセットと MultipleNegativesRankingLoss 損失を使用してこの同じモデルを微調整しました。
Sentence Transformers の制限は何か?
Sentence Transformers モデルは意味検索に対しては単純な Transformers モデルよりも遥かに上手く機能します。けれども、Sentence Transformers が上手く機能しない場所はどこでしょう?貴方のタスクが分類であれば、センテンス埋め込みは間違ったアプローチです。その場合には、🤗 Transformers ライブラリ はより良い選択です。
Extra Resources
- Getting Started With Embeddings.
- Understanding Semantic Search.
- Start your first Sentence Transformers model.
- Generate playlists using Sentence Transformers.
- Hugging Face + Sentence Transformers docs.
Thanks for reading! Happy embedding making.
以上