PyTorch 1.9.0 リリースノート (翻訳)
翻訳 : (株)クラスキャット セールスインフォメーション
日時 : 06/21/2021
* 本ページは PyTorch 1.9.0 リリースノートの Highlights と関連ブログ記事を翻訳したものです:
- https://github.com/pytorch/pytorch/releases/tag/v1.9.0
- PyTorch 1.9 Release, including Torch.Linalg and Mobile Interpreter

- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- Windows PC のブラウザからご参加が可能です。スマートデバイスもご利用可能です。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ |
| Facebook: https://www.facebook.com/ClassCatJP/ |
Torch.Linalg とモバイル・インタープリタを含む、PyTorch 1.9 リリース
We are excited to announce the release of PyTorch 1.9. このリリースは 398 contributors により行なわれた、1.8 からの 3,400 コミット以上から構成されます。リリースノートは ここ で利用可能です。ハイライトは以下を含みます :
- torch.linalg, torch.special と複素 Autograd を含む、科学計算をサポートするための主要な改良
- モバイル・インタープリタによる on-device バイナリサイズの主要な改良
- TorchElastic の PyTorch Core へのアップストリームを通した elastic-耐障害性訓練のネイティブサポート
- GPU サポートを持つ大規模分散訓練をサポートするための PyTorch RPC フレームワークへの主要なアップデート
- パフォーマンスを最適化してモデル推論配備のためのパッケージ化のための新しい API
- PyTorch Profile の分散訓練、GPU 使用と SM 効率性のサポート
1.9 とともに、PyTorch ライブラリへのメジャー・アップデートもリリースしています、これについて このブログ投稿 で読むことができます。
We’d like to thank the community for their support and work on this latest release. We’d especially like to thank Quansight and Microsoft for their contributions.
PyTorch の機能は Stable、Beta と Prototype に分類されます。このブログ投稿 で定義について更に学習できます。
Frontend APIs
(Stable) torch.linalg
1.9 では、torch.linalg モジュールがステーブル・リリースに移行しています。線形代数は深層学習と科学計算に不可欠で、torch.linalg モジュールはそのために torch.linalg.matrix_norm と torch.linalg.householder_product のように、NumPy の線形代数モジュール 等々からの総ての関数の実装により PyTorch のサポートを拡張しています (現在はアクセラレータと autograd のサポート)。これはモジュールを NumPy で作業したことのあるユーザに直ちに馴染ませます。ここで ドキュメント を参照してください。
来週 torch.linalg モジュールについての詳細を持つ別のブログ投稿を公開する予定です!
(Stable) 複素 Autograd
PyTorch 1.8 で beta としてリリースされた 複素 Autograd 機能は今ではステーブルです。beta リリースから、PyTorch 1.9 の 98% 以上の演算子のために 複素 Autograd のためのサポートを拡張してきました、より多くの OpInfo を追加することにより複素演算子のためのテストを改良し、そして TorchAudio の native 複素 tensor へのマイグレーションを通してより素晴らしい検証を追加しました (この issue 参照)。
この機能は複素勾配を計算し実数変数の損失関数を複素変数で最適化する機能をユーザに提供します。これは TorchAudio, ESPNet, Asteroid と FastMRI のような PyTorch の複素数の multiple current downstream prospective ユーザのために必要な機能です。詳細は ドキュメント を参照してください。
(Stable) torch.use_deterministic_algorithms()
デバッグと再現可能なプログラムを書く支援をするために、PyTorch 1.9 は torch.use_determinstic_algorithms オプションを含みます。この設定が有効にされたとき、可能であれば、演算は決定論的に動作し、非決定論的に動作するかもしれない場合には実行時エラーを投げます。ここに 2, 3 のサンプルがあります :
>>> a = torch.randn(100, 100, 100, device='cuda').to_sparse()
>>> b = torch.randn(100, 100, 100, device='cuda')
# Sparse-dense CUDA bmm is usually nondeterministic
>>> torch.bmm(a, b).eq(torch.bmm(a, b)).all().item()
False
>>> torch.use_deterministic_algorithms(True)
# Now torch.bmm gives the same result each time, but with reduced performance
>>> torch.bmm(a, b).eq(torch.bmm(a, b)).all().item()
True
# CUDA kthvalue has no deterministic algorithm, so it throws a runtime error
>>> torch.zeros(10000, device='cuda').kthvalue(1)
RuntimeError: kthvalue CUDA does not have a deterministic implementation...
PyTorch 1.9 は accum=False を伴う index_add, index_copy と index_put も含む、多くのインデキシング演算のための決定論的実装を追加しています。詳細については、ドキュメント と 再現性ノート を参照してください。
(Beta) torch.special
SciPy の special モジュール への類推である、torch.special モジュールは今では beta で利用可能です。このモジュールは iv, ive, erfcx, logerfc と logerfcx のような科学計算と分布で作業するために有用な多くの関数を含みます。詳細は ドキュメント を参照してください。
(Beta) nn.Module パラメータ化
nn.Module パラメータ化はユーザに nn.Module の任意のパラメータやバッファを (nn.Module 自身を変更することなく) パラメータ化することを可能にします。それはパラメータが存在する空間を特殊な最適化メソッドを必要とすることなく制約することを可能にします。
これはまた PyTorch 1.9 のための spectral_norm パラメータ化の新しい実装も含みます。機能が 1.10 でステーブルになるように更なるパラメータ化がこの機能に追加されます (weight_norm、行列制約 と pruning の一部) 。詳細については、ドキュメント と チュートリアル を参照してください。
PyTorch モバイル
(Beta) モバイル・インタープリタ
PyTorch ランタイムの streamlined バージョン、モバイル・インタープリタを Beta でリリースしています。インタープリタは PyTorch プログラムを削減されたバイナリサイズ・フットプリントでエッジデバイスで実行します。
モバイル・インタープリタは PyTorch モバイルのために最もリクエストされた機能の一つです。この新しいリリースは現在のオンデバイス・ランタイムに比べてバイナリサイズを大幅に削減しています。(典型的なアプリケーションのためにバイナリサイズを ~75% まで削減できる) インタープリタでバイナリサイズの改良を得るためにはこれらの手順に従ってください。例として、モバイル・インタープリタを使用して、arm64-v7a Android で MobileNetV2 は圧縮され 2.6 MB に到達します。この最新のリリースでは iOS と Android のために事前ビルドされたライブラリを提供することでインタープリタを統合することを遥かに単純にしています。
TorchVision ライブラリ
1.9 から、ユーザは iOS/Android apps 上で TorchVision ライブラリを利用できます。TorchVision ライブラリは C++ TorchVision ops を含み iOS についてはメイン PyTorch ライブラリと一緒にリンクされる必要があり、Android についてはそれは gradle 依存性として追加できます。これはオブジェクト検出とセグメンテーションのための TorchVision ビルド済み MaskRCNN 演算子の使用を可能にします。ライブラリについて更に学習するには、チュートリアルと デモ apps を参照してください。
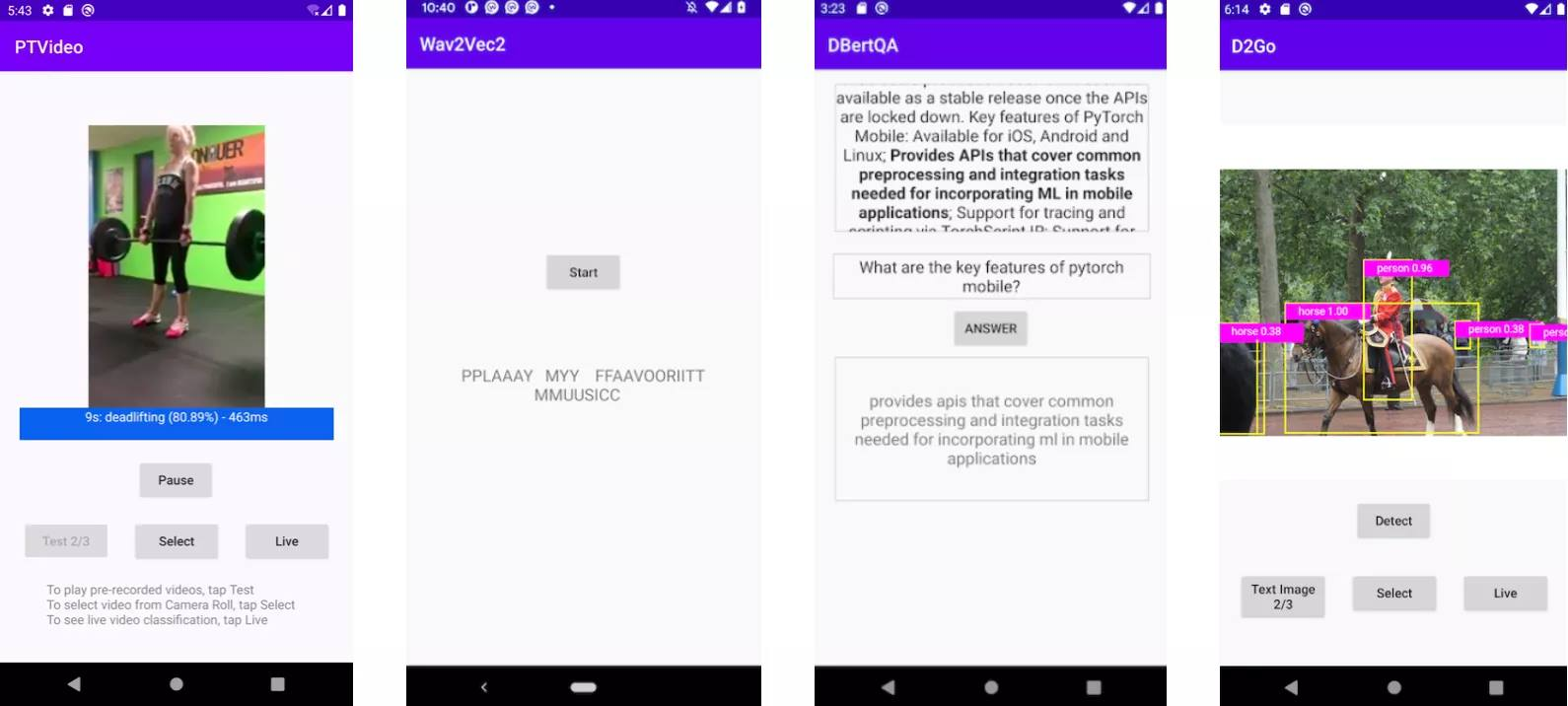
デモ apps
PyTorch Video ライブラリに基づく新しいビデオ app と最新の torchaudio, wave2vec モデルに基づくアップデートされた音声認識 app をリリースしています。両者は iOS と Android で利用可能です。加えて、PyTorch Mobile v1.9 とともに、7 つのコンピュータビジョンと 3 つの自然言語処理デモ apps をアップデートしました、これらは HuggingFace DistilBERT と DeiT ビジョン transformer モデルを含みます。これら 2 つの apps の追加により、今では画像、テキスト、音声と動画をカバーするデモ apps の完全なスーツを提供します。始めるには iOS デモ apps と Android デモ apps を調べてください。
分散訓練
(Beta) TorchElastic は今ではコアの一部
pytorch/elastic github レポジトリで 1 年以上前にオープンソース化された TorchElastic は PyTorch ワーカー・プロセスのためのランナーとコーディネータです。それ以来、それは様々な分散 torch ユースケースで採用されてきました : 1) deepspeech.pytorch 2) pytorch-lightning 3) Kubernetes CRD. 今では、それは PyTorch コアの一部です。
その名前が示すように、TorchElastic のコア関数はスケーリング・イベントを優雅に (= gracefully) 処理します。elasticity (弾性) の注目すべき結果はピア検出とランク割当てが TorchElastic に組み込まれていてユーザがギャング (= gang, 集団) スケジューラを必要とすることなく先取り可能な (= preemptible) インスタンス上で分散訓練を実行することを可能にします。ついでに言えば、etcd は (かつては) TorchElastic の強い依存性でした。アップストリームでは、これはもはや当てはまりません、c10d::Store に基づく「スタンドアロン」rendezvous を追加したからです。詳細は、ドキュメント を参照してください。
(Beta) 分散訓練アップデート
TorchElastic に加えて、distributed パッケージで利用可能な幾つかの beta 機能があります :
- (Beta) RPC で CUDA サポートが利用可能 : CPU RPC と汎用 RPC フレームワークと比較して、CUDA RPC は P2P Tensor 通信のために遥かに効率的な方法です。それは TensorPipe の上に構築されます、これは Tensor デバイス型と caller と callee の両者の上のチャネル可用性に基づいて各 Tensor のために自動的に通信チャネルを選択できます。既存の TensorPipe チャネルは NVLink, InfiniBand, SHM, CMA, TCP 等をカバーします。CUDA RPC が CPU RPC に比較して 34x スピードアップを達成することをどのように支援するかについての このレシピ を見てください。
- (Beta) ZeroRedundancyOptimizer : ZeroRedundancyOptimizer はプロセス毎 optimizer 状態のサイズを縮小するために DistributedDataParallel と連携して使用できます。ZeroRedundancyOptimizer のアイデアは DeepSpeed/ZeRO プロジェクト と Marian に由来し、そこでは各プロセスの optimizer はモデルパラメータのシャードと対応する optimizer 状態を所有します。step() を実行するとき、各 optimizer はそれ自身のパラメータだけを更新し、そして総てのプロセスに渡り更新されたパラメータを同期するためにコレクティブ通信を使用します。更に学習するためには このドキュメント とこの チュートリアル を参照してください。
- (Beta) 分散コレクティブのプロファイリングのサポート : PyTorch の profiler ツール、torch.profiler と torch.autograd.profiler は分散コレクティブと allreduce, alltoall, allgather, send/recv 等を含む point to point 通信プリミティブをプロファイルすることができます。これは PyTorch によりネイティブに支援される総てのバックエンドのために有効にされます : gloo, mpi と nccl. これはパフォーマンス問題のデバッグ、分散通信を含むトレースの解析、そして分散訓練を利用するアプリケーションのパフォーマンスへの洞察を得るために利用できます。更に学習するには、このドキュメント を参照してください。
パフォーマンス最適化とツール
(Stable) Freezing API
モジュール凍結はモジュールのパラメータと属性値を定数として TorchScript 内部表現としてインライン化するプロセスです。これは TorchScript 最適化と他のバックエンドに落とす (= lower) 両者のために更なる最適化と貴方のプログラムの特殊化を可能にします。それは optimize_for_mobile API, ONNX 等で使用されます。
凍結はモデル配備のために勧められます。これは TorchScript JIT 最適化がオーバーヘッドと PyTorch モデルの訓練、調整とデバッグのために必要なブックキーピングを最適化するのに役立ちます。それは Conv-BN の融合のような、非凍結グラフ上では意味的に有効ではないグラフの融合を可能にします。詳細は、ドキュメント を参照してください。
(Beta) PyTorch Profiler
新しい PyTorch Profiler は beta に移行して GPU profiling のために Kineto を、可視化のために TensorBoard を活用し、そして今ではチュートリアルとドキュメントに渡り標準です。
PyTorch 1.9 は Windows と Mac を含む、より多くのビルドに新しい torch.profiler API のためのサポートを拡張しています、そして殆どの場合以前の torch.autograd.profiler API の代わりに勧められます。新しい API は既存の profiler 機能をサポートし、on-device CUDA カーネルをトレースして long-running ジョブのためのサポートを提供するために CUPTI ライブラリ (Linux-only) と統合しています、例えば :
def trace_handler(p):
output = p.key_averages().table(sort_by="self_cuda_time_total", row_limit=10)
print(output)
p.export_chrome_trace("/tmp/trace_" + str(p.step_num) + ".json")
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
# schedule argument specifies the iterations on which the profiler is active
schedule=torch.profiler.schedule(
wait=1,
warmup=1,
active=2),
# on_trace_ready argument specifies the handler for the traces
on_trace_ready=trace_handler
) as p:
for idx in range(8):
model(inputs)
# profiler will trace iterations 2 and 3, and then 6 and 7 (counting from zero)
p.step()
より多くの使用例は profiler レシピページ で見つけられます。
PyTorch Profiler TensorBoard プラグインは以下のための新しい機能を持ちます :
- NCCL のための通信概要を伴う分散訓練要約ビュー
- Trace ビューと GPU 演算子ビューの GPU 使用量と SM 効率性
- メモリ Profiling ビュー
- Microsoft VSCode から起動されたときソースにジャンプ
- クラウド・オブジェクトストレージ・システムからのトレースのロードのための機能
(Beta) 推論モード API
推論モード API は、安全であるまま不正な勾配が決して計算できないことを確実にしながら、推論ワークロードのための大幅なスピードアップを可能にします。それは autograd が必要とされないとき最善の可能なパフォーマンスを提供します。
より詳細については、推論モード自体のためのドキュメント と それをいつ使用するか no_grad モードとの違いを説明するドキュメント を参照してください。
(Beta) torch.package
torch.package は PyTorch モデルを自己充足的な、ステーブル形式でパッケージ化する新しい方法です。パッケージはモデルのデータ (e.g. パラメータ、バッファ) とそのコード (モデル・アーキテクチャ) の両者を含みます。モデルを (ピン止めされたバージョンを持つ conda 環境の記述と連結された) Python 依存性の完全なセットと共にパッケージ化することは訓練を容易に再生成するために利用できます。自己充足的な抽象でモデルを表すことはまた、pure-Python 表現の柔軟性を達成しながら、それが公開されて製品 ML パイプラインを通して転送されることを可能にします。詳細については、ドキュメント を参照してください。
(Prototype) prepare_for_inference
prepare_for_inference は新しいプロトタイプ機能で、モジュールを取りそしてデバイスに依存した、推論パフォーマンスを改善するためにグラフレベルの最適化を遂行します。それはユーザのワークフローに最小限の変更を必要とする PyTorch ネイティブ・オプションであることを意味します。詳細については、ここ の TorchScript バージョンか ここ の FX バージョンのための ドキュメント を見てください。
(Prototype) TorchScript の Profile-directed 型付け
TorchScript はコンパイルが成功するためにソースコードが型アノテーションを持つという厳しい要件を持ちます。長い間、試行錯誤により (i.e. torch.jit.script により生成された型チェックエラーを一つずつ修正することにより) 欠落したまたは不正な型アノテーションを追加することだけが可能でした、これは非効率的で時間を消費しました。今では、MonkeyType のような既存のツールを活用することにより torch.jit.script のための profile directed 型付けを可能にしました、これはプロセスを遥かに容易に、高速に、そして更に効率的にします。詳細については、ドキュメント を参照してください。
Thanks for reading. If you’re interested in these updates and want to join the PyTorch community, we encourage you to join the discussion forums and open GitHub issues. To get the latest news from PyTorch, follow us on Facebook, Twitter, Medium, YouTube, or LinkedIn.
Cheers!
Team PyTorch
以上