PyTorch 1.8 チュートリアル : 並列と分散訓練 : 単一マシン並列ベストプラクティス (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/10/2021 (1.8.1+cu102)
* 本ページは、PyTorch 1.8 Tutorials の以下のページを翻訳した上で適宜、補足説明したものです:
- Parallel and Distributed Training : Single-Machine Model Parallel Best Practices
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

スケジュールは弊社 公式 Web サイト でご確認頂けます。
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。) | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |
並列と分散訓練 : 単一マシン並列ベストプラクティス
モデル並列は分散訓練テクニックで広く利用されます。以前の投稿はマルチ GPU 上でニューラルネットワークを訓練するために DataParallel をどのように使用するか説明しました ; この機能は同じモデルを総ての GPU に対して複製し、そこでは各 GPU は入力データの異なるパーティションを消費します。それは訓練プロセスを大幅に高速化できますが、それは幾つかのユースケースについては機能しません、そこではモデルが大規模過ぎて単一 GPU に収まりません。この投稿はモデル並列を使用してその問題をどのように解くかを示します、これは DataParallel とは対照的に、各 GPU にモデル全体を複製するのではなく単一モデルを異なる GPU 上に分割します (具体的には、モデル m が 10 層を含むと仮定すると : DataParallel を使用するとき、各 GPU はこれら 10 層の各々のレプリカを持つ一方で、2 つの GPU 上でモデル並列を使用するとき、各 GPU は 5 層をホストできるでしょう)。
モデル並列の高位のアイデアはモデルの異なるサブネットワークを異なるデバイスに配置して、それに従って中間出力をデバイスに渡り移すように forward メソッドを実装することです。モデルの一部だけが任意の個々のデバイス上で動作するので、デバイスのセットはより大規模なモデルに集合的に対応できます。この投稿では、大規模なモデルを構築してそれらを GPU の制限された数に押し込めることを試しません。代わりに、この投稿はモデル並列のアイデアを示すことに焦点を当てます。このアイデアを現実世界のアプリケーションに適用することは読者に委ねます。
Note: モデルが複数のサーバに渡る分散モデル並列訓練については、サンプルと詳細のために Getting Started With Distributed RPC フレームワーク を参照してください。
基本的な使用方法
2 つの線形層を含む toy モデルから始めましょう。このモデルを 2 つの GPU を実行するためには、単純に各線形層を異なる GPU 上に配置し、そしてそれに従って層デバイスに適合するように入力と中間出力を移動します。
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
線形層と tensor を正しいデバイスに配置する 4 つの to(device) 呼び出しを除いて、上の ToyModel は単一 GPU 上でそれをどのように実装するかに非常に類似して見えることに注意してください。それがモデルの変更を必要とする唯一の場所です。backward() と torch.optim はモデルが 1 つの GPU 上にあるかのように勾配を自動的に処理します。損失関数を呼び出すときラベルが出力と同じデバイス上にあることを確かにする必要があるだけです。
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()
既存のモジュールにモデル並列を適用する
既存の単一 GPU モジュールを数行の変更だけでマルチ GPU 上で実行することも可能です。下のコードは torchvision.models.resnet50() を 2 つの GPU にどのように分解するかを示します。アイデアは既存の ResNet モジュールから継承して、コンストラクションの間に層を 2 つの GPU に分割することです。そして 2 つのサブネットワークをそれに応じて中間出力を移動して縫い合わせるように forward メソッドを override します。
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
上の実装はモデルが大きすぎて単一 GPU に収まらないケースについて問題を解決します。けれども、モデルが収まるならば単一 GPU 上でそれを実行するよりも遅くなることに既に気付いたかもしれません。時間のどのポイントでも、2 つの GPU の 1 つだけが動作している一方で、他方の一つは何もせずにそこに在るためです。layer2 と layer3 の間で中間出力が cuda:0 から cuda:1 にコピーされる必要がありますのでパフォーマンスは更に劣化します。
実行時間の定量的な知見を得るために実験を実行しましょう。この実験では、ModelParallelResNet50 と既存の torchvision.models.resnet50() をランダム入力とラベルをそれらに供給することで訓練します。訓練後、モデルはどのような有用な予測も生成しませんが、実行時間の合理的な理解が得られます。
import torchvision.models as models
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def train(model):
model.train(True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
for _ in range(num_batches):
# generate random inputs and labels
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, one_hot_indices, 1)
# run forward pass
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
# run backward pass
labels = labels.to(outputs.device)
loss_fn(outputs, labels).backward()
optimizer.step()
上の train(model) メソッドは損失関数として nn.MSELoss を、そして optimizer として optim.SGD を使用します。それは 128 X 128 画像上での訓練を模倣します、これは 3 バッチに体系化され、そこでは各バッチは 120 画像を含みます。そして、timeit を使用して train(model) メソッドを 10 回実行し、そして標準偏差で実行時間をプロットします。
import matplotlib.pyplot as plt
plt.switch_backend('Agg')
import numpy as np
import timeit
num_repeat = 10
stmt = "train(model)"
setup = "model = ModelParallelResNet50()"
mp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
mp_mean, mp_std = np.mean(mp_run_times), np.std(mp_run_times)
setup = "import torchvision.models as models;" + \
"model = models.resnet50(num_classes=num_classes).to('cuda:0')"
rn_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
rn_mean, rn_std = np.mean(rn_run_times), np.std(rn_run_times)
def plot(means, stds, labels, fig_name):
fig, ax = plt.subplots()
ax.bar(np.arange(len(means)), means, yerr=stds,
align='center', alpha=0.5, ecolor='red', capsize=10, width=0.6)
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xticks(np.arange(len(means)))
ax.set_xticklabels(labels)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig(fig_name)
plt.close(fig)
plot([mp_mean, rn_mean],
[mp_std, rn_std],
['Model Parallel', 'Single GPU'],
'mp_vs_rn.png')
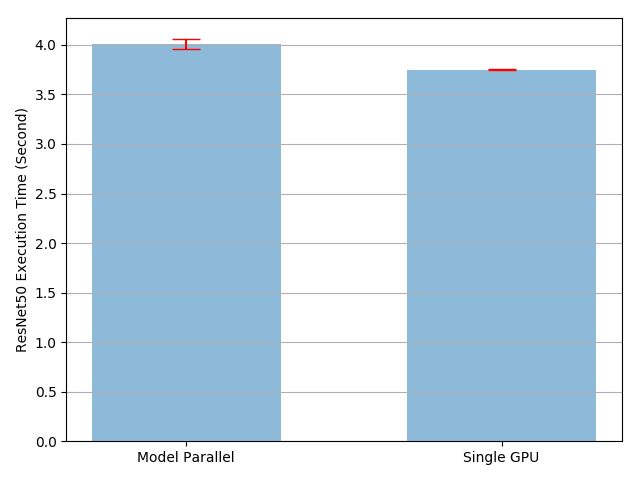
結果は、モデル並列実装の実行時間は既存の単一 GPU 実装よりも 4.02/3.75-1=7% 長いことを示しています。そのため GPU 間で tensor をコピーして戻すおおよそ 7% のオーバーヘッドがあると結論付けることができます。実行を通して 2 つの GPU の一つはアイドルしたままであることを知っていますので、改良の余地があります。一つのオプションは各バッチを分割のパイプラインに更に分けることです、一つの分割が 2 番目のサブネットワークに到達するとき、続く分割は最初のサブネットワークに供給できるようにです。このようにして、2 つの連続する分割は 2 つの GPU 上で同時に実行できます。
パイプライン入力によるスピードアップ
以下の実験では、各 120 画像バッチを 20 画像分割に更に分けます。PyTorch は CUDA 演算を非同期に起動しますので、実装は同時並列性 (= concurrency) を獲得するために複数のスレッドを spawn する必要はありません。
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. s_prev runs on cuda:1
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. s_next runs on cuda:0, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_vs_rn_vs_pp.png')
device-to-device tensor コピー演算はコピー元とコピー先デバイス上の現在のストリーム上で同期されることに注意してください。複数のストリームを作成する場合、コピー演算が正しく同期されていることを確実にしなければなりません。コピー演算が終了する前にソース tensor を書いたりコピー先 tensor を読み書きすると未定義の動作に繋がる可能性があります。上の実装はソースとコピー先デバイスの両者の上でデフォルト・ストリームだけを使用していますので、追加の同期を強制する必要はありません。

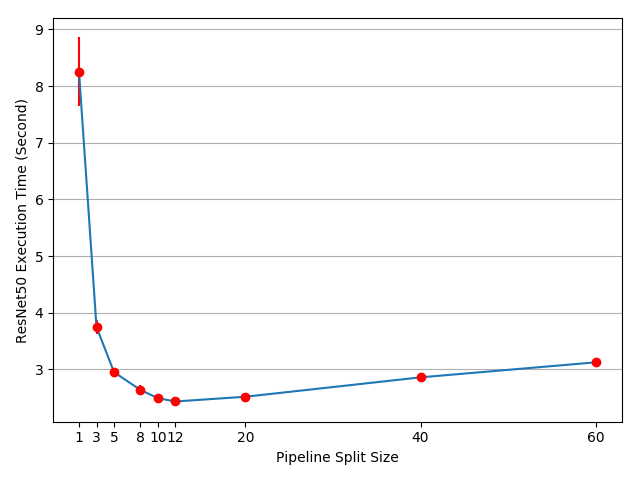
実験結果は、モデル並列 ResNet 50 への入力のパイプライン化は訓練プロセスをおよそ 3.75/2.51-1=49% スピードアップすることを示しています。理想的な 100% スピードアップから依然としてかなり遠いです。パイプライン並列実装では新しいパラメータ split_sizes を導入したので、 新しいパラメータが訓練時間全体にどのように影響を与えるか不明瞭です。直観的に言えば、小さい split_size の使用は多くの tiny CUDA カーネル起動に繋がる一方で、大きい split_size の使用は最初と最後の分割で比較的長いアイドル時間という結果になります。いずれも最適ではありません。この特定の実験のために最適な split_size 設定があるかもしれません。幾つかの異なる split_size 値を使用して実験を実行することによりそれを見つけようとしましょう。
means = []
stds = []
split_sizes = [1, 3, 5, 8, 10, 12, 20, 40, 60]
for split_size in split_sizes:
setup = "model = PipelineParallelResNet50(split_size=%d)" % split_size
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
means.append(np.mean(pp_run_times))
stds.append(np.std(pp_run_times))
fig, ax = plt.subplots()
ax.plot(split_sizes, means)
ax.errorbar(split_sizes, means, yerr=stds, ecolor='red', fmt='ro')
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xlabel('Pipeline Split Size')
ax.set_xticks(split_sizes)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig("split_size_tradeoff.png")
plt.close(fig)
結果は split_size を 12 に設定すると最速の訓練スピードを得られ、これは 3.75/2.43-1=54% スピードアップに繋がることを示しています。訓練プロセスを更に加速する機会は依然としてあります。例えば、cuda:0 上の総ての演算はデフォルト・ストリームに配置されます。それは次の分割上の計算は前の分割のコピー演算とオーバーラップできないことを意味します。しかしながら、前と次の分割は異なる tensor ですので、計算を他のもののコピーとオーバーラップさせても問題はありません。実装は両者の GPU 上で複数のストリームを利用する必要があり、異なるサブネットワーク構造は異なるストリーム管理ストラテジーを必要とします。総てのモデル並列ユースケースのために動作する一般的なマルチストリーム解法はありませんので、このチュートリアルではそれを議論しません。
Note : この記事は幾つかのパフォーマンス測定を示しています。貴方自身のマシン上で同じコードを実行するとき異なる数値を見るかもしれません、何故ならば結果は基礎となるハードウェアとソフトウェアに依存するからです。貴方の環境のための最善のパフォーマンスを得るに、正しいアプローチは最善の分割サイズを見出すために最初に曲線を生成してから、その分割サイズをパイプライン入力に使うことです。
以上